
 第 9 章 字符串 字符和字节
第 9 章 字符串 字符和字节
# 第 9 章 字符串 字符和字节
书本内容

# 9.1 字符串基础
书本内容

# 9.2 字符串长度
书本内容

# 9.3 不受限制的字符串函数
书本内容

# 9.3.1 复制字符串
书本内容

# 9.3.2 连接字符串
书本内容

# 9.3.3 函数的返回值
书本内容

# 9.3.4 字符串比较
书本内容

# 9.4 长度受限的字符串函数
书本内容

# 9.5 字符串查找基础
书本内容

# 9.5.1 查找一个字符
书本内容

# 9.5.2 查找任何几个字符
书本内容

笔记
The strpbrk ("string pointer break") function is related to strcspn, except that it returns a pointer to the first character in string that is a member of the set stopset instead of the length of the initial substring. It returns a null pointer if no such character from stopset is found.
# 9.5.3 查找一个子串
书本内容

# 9.6 高级字符串查找
书本内容

# 9.6.1 查找一个字符串前缀
书本内容

# 9.6.2 查找标记
书本内容

# 9.7 错误信息
书本内容

# 9.8 字符操作
书本内容

# 9.8.1 字符分类
书本内容

isprint 的描述在 Linux 下有误
- 应该包括空格,而不是空白字符
- 其不包括
\n等空白字符
- 其不包括
# 9.8.2 字符转换
书本内容

# 9.9 内存操作
书本内容

# 9.10 总结
书本内容

# 9.13 问题
#
问题 1
C语言缺少显式的字符串数据类型,这是一个优点还是一个缺点?
答案
优点
- 操纵字符数组的效率和访问的灵活性
缺点
- 有可能引起错误:溢出数组,使用的下标超出了字符串的边界
- 无法改变任何用于保存字符串的数组的长度等
现代的面向对象的技术中的字符串类毫无例外地包括了完整的错误检查、用于字符串的动态内存分配和其他一些防护措施
- 这些措施都会造成效率上的损失
- 但是,如果程序无法运行,效率再高也没有什么意义
- 而且,较之设计C语言的时代,现代软件项目的规模要大得多
由于这个方法内在的危险性,所以使用现代的高级的、完整的字符串类还是物有所值的
但如果C程序员愿意循规蹈矩地使用字符串,也可以获得上述优点
#
问题 2
strlen 函数返回一个无符号量 (size_t) ,为什么这里无符号值比有符号值更合适?但返回无符号值其实也有缺点,为什么?
答案
- 优点
- 无符号值更加符合具体含义,因为字符串的长度不可能是负值
- 在同等的字节数下,无符号值表示的范围比有符号值大,可能返回更长的字符串的长度
- 缺点
- 涉及无符号值的运算极易因疏忽而出现问题
#
问题 3
如果 strcat 和 strcpy 函数返回一个指向目标字符串末尾的指针,和事实上返回一个指向目标字符串起始位置的指针相比,有没有什么优点?
答案
- 优点是可以更加高效的完成后续的串联操作,因为不再需要重复的查找字符串的末尾
#
问题 4
如果从数组 x 复制 50 个字节到数组 y ,最简单的方法是什么?
答案
- 不能直接使用
str---函数,因为此类函数碰到第 1 个\0(NUL) 字节时,即会停止 - 可以使用
memcpy进行内存复制memcpy(y, x, 50)
#
问题 5
假定你有一个名叫 buffer 的数组,它的长度为 BSIZE 个字节,你用下面这条语句把一个字符串复制到这个数组:
strncpy( buffer, some_other_string, BSIZE - 1 );
它能不能保证 buffer 中的内容是一个有效的字符串?
答案
不能,因为当
strlen(some_other_string) >= strlen(buffer)时,strncpy不能保证 buffer 以NUL字节结尾为了确保不发生错误,可按下列语句操作
char buffer[BSIZE]; ... strncpy(buffer, name, BSIZE); buffer[BSIZE - 1] = '\0'1
2
3
4参照 长度受限的字符串函数
#
问题 6
用下面这种方法
if( isalpha( ch ) ){
取代下面这种显式的测试有什么优点?
if( ch >= 'A' && ch <= 'Z' || ch >= 'a' && ch <= 'z' ){
答案
- 前者适用于任何字符集,而后者只适合
ASCII码 - 前者的可移植性较强,后者可移植性较差
#
问题 7
下面的代码怎样进行简化?
for( p_str = message; *p_str != '\0'; p_str++ ){
if( islower( *p_str ) )
*p_str = toupper( *p_str );
}
2
3
4
答案
for( p_str = message; *p_str != '\0'; p_str++ )
*p_str = toupper( *p_str );
2
#
问题 8
下面的表达式有何不同?
memchr( buffer, 0, SIZE ) - buffer
strlen( buffer )
2
答案
如果缓冲区(
buffer[0] ~ buffer[SIZE-1])包含了一个字符串(即包含了一个NUL字节)memchr将在内存中buffer的起始位置开始查找第1个包含0的字节并返回一个指向该字节的指针。将这个指针减去buffer将获得存储在这个缓冲区中的字符串的长度strlen函数完成相同的任务
不过
strlen的返回值是个无符号size_t类型的值- 而指针减法的值应该是个有符号类型
(ptrdiff_t)
但是,如果缓冲区(
buffer[0] ~ buffer[SIZE-1])内的数据并不是以NUL字节结尾memchr函数将返回一个NULL指针。将这个值减去buffer将产生一个无意义的结果strlen函数在数组的后面继续查找,直到最终发现一个NUL字节
# 9.14 编程练习
#
编程练习 1
编写一个程序,从标准输入读取一些字符,并统计下列各类字符所占的百分比。
控制字符
空白字符
数字
小写字母
大写字母
标点符号
不可打印的字符
2
3
4
5
6
7
请使用在 ctype.h 头文件中定义的字符分类函数
答案
代码
#include <stdio.h> #include <stdlib.h> #include <ctype.h> int main(void) { int ch; int n_ctrls = 0; int n_spaces = 0; int n_digits = 0; int n_lowers = 0; int n_uppers = 0; int n_puncts = 0; int n_nprints = 0; int total = 0; while ((ch = getchar()) != EOF) { if (iscntrl(ch)) n_ctrls++; if (isspace(ch)) n_spaces++; if (isdigit(ch)) n_digits++; if (islower(ch)) n_lowers++; if (isupper(ch)) n_uppers++; if (ispunct(ch)) n_puncts++; if (!isprint(ch)) n_nprints++; total++; } if (total == 0) printf("No characters in the input!\n"); else { printf("%3.0f%% control characters\n", n_ctrls * 100.0 / total); printf("%3.0f%% whitespace characters\n", n_spaces * 100.0 / total); printf("%3.0f%% digits\n", n_digits * 100.0 / total); printf("%3.0f%% lower case letters\n", n_lowers * 100.0 / total); printf("%3.0f%% upper case letters\n", n_uppers * 100.0 / total); printf("%3.0f%% punctuation characters\n", n_puncts * 100.0 / total); printf("%3.0f%% non-printable characters\n", n_nprints * 100.0 / total); } return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
提示
- 参照 字符分类
#
编程练习 2
编写一个名叫 my_strlen 的函数。它类似于 strlen 函数,但它能够处理由于使用 strn--- 函数而创建的未以 NUL 字节结尾的字符串。你需要向函数传递一个参数,它的值就是保存了需要进行长度测试的字符串的数组的长度
答案
代码
/* ** Safe string length. Returns the length of a string that ** is possibly not NUL-terminated. 'size' is the length of the ** buffer in which this string is stored. */ #include <stddef.h> size_t my_strnlen(char const *string, size_t size) { size_t length; for (length = 0; length < size; length++) if (*string++ == '\0') break; return length; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
参考
size_t定义在stddef.h(opens new window) 中stddef.h已经包含在了string.h中
#
编程练习 3
编写一个名叫 my_strcpy 的函数。它类似于 strcpy 函数,但它不会溢出目标数组。复制的结果必须是一个真正的字符串
答案
代码
/* ** Safe string copy */ #include <string.h> char *my_strcpy(char *dest, char *src, size_t size) { strncpy(dest, src, size); dest[size - 1] = '\0'; return dest; }1
2
3
4
5
6
7
8
9
10
11
12
13
#
编程练习 4
编写一个名叫 my_strcat 的函数。它类似于 strcat 函数,但它不会溢出目标数组。它的结果必须是一个真正的字符串
答案
代码
#include <string.h> #include "my_string.h" /* ** Safe string concatenation. ** size is the length of dest buffer */ char *my_strcat(char *dest, char *src, size_t size) { size_t remain_size; remain_size = size - my_strnlen(dest, size); if (remain_size > 1) strncat(dest, src, remain_size - 1); /* ** Make sure the result is a real string */ dest[size - 1] = '\0'; return dest; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22my_string.h对应的代码如下
#include <stddef.h> size_t my_strnlen(char const *string, size_t size); char *my_strcat(char *dest, char *src, size_t size);1
2
3my_strnlen函数对应的代码见编程练习2
提示
dest中可能不含有\0,因此要用编程练习 2 中的my_strnlen函数来判断字符串的长度- 当
remain_size == 1时,此时不能再使用strncat进行字符的拼接- 因为
strncat会在复制1个字符后再添加1个NUL字节 - 此时会向
dest缓存区外的一个字节进入写入操作,可能会造成意想不到的结果
- 因为
- 注意
size_t是无符号整数,对其进行减法运算时,要特别在意
#
编程练习 5
编写函数
void my_strncat( char *dest, char *src, int dest_len );
它用于把 src 中的字符串连接到 dest 中原有字符串的末尾,但它保证不会溢出长度为 dest_len 的 dest 数组。和 strncat 函数不同,这个函数也考虑原先存在于 dest 数组的字符串长度,因此能够保证不会超越数组边界。
答案
基本可以借助第 4 题中的代码实现相关的功能
代码
#include "my_string.h" void my_strncat(char *dest, char *src, int dest_len) { my_strcat(dest, src, dest_len); }1
2
3
4
5
6
#
编程练习 6
编写一个名叫 my_strcpy_end 的函数取代 strcpy 函数,它返回一个指向目标字符串末尾的指针(也就是说,指向 NUL 字节的指针),而不是返回一个指向目标字符串起始位置的指针
答案
代码
#include <string.h> char *my_strcpy_end(char *dest, char const *src) { while ((*dest++ = *src++) != '\0') ; return dest - 1; }1
2
3
4
5
6
7
8
9
#
编程练习 7
编写一个名叫 my_strchr 的函数,它的原型如下:
char *my_strchr( char const *str, int ch );
这个函数类似于 strchr 函数,只是它返回的是一个指向 ch 字符在 str 字符串中最后一次出现(最右边)的位置的指针
答案
代码
#include <string.h> char *my_strchr(char const *str, int ch) { char const *prev; prev = NULL; for (; (str = strchr(str, ch)) != NULL; str++) prev = str; return (char *)prev; }1
2
3
4
5
6
7
8
9
10
11
12
#
编程练习 8
编写一个名叫 my_strnchr 的函数,它的原型如下
char *my_strnchr( char const *str, int ch, int which );
这个函数类似于 strchr 函数,但它的第 3 个参数指定 ch 字符在 str 字符串中第几次出现。例如,如果第 3 个参数为 1 ,这个函数的功能就和 strchr 完全一样。如果第 3 个参数为 2 ,这个函数就返回一个指向 ch 字符在 str 字符串中第 2 次出现的位置的指针。
答案
代码
#include <string.h> char *my_strnchr(char const *str, int ch, int which) { char const *prev; prev = NULL; for (; --which >= 0 && (str = strchr(str, ch)) != NULL; str++) prev = str; if (which == 0) return (char *)prev; else return NULL; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#
编程练习 9
编写一个函数,它的原型如下:
int count_chars( char const *str, char const *chars );
函数应该在第1个参数中进行查找,并返回匹配第2个参数所包含的字符的数量。
答案
代码
#include <string.h> int count_chars(char const *str, char const *chars) { int count; count = 0; for (; (str = strpbrk(str, chars)) != NULL; str++) count++; return count; }1
2
3
4
5
6
7
8
9
10
11
12
#
编程练习 10
编写函数
int palindrome( char *string );
如果参数字符串是个回文,函数就返回真,否则就返回假。回文就是指一个字符串从左向右读和从右向左读是一样的。函数应该忽略所有的非字母字符,而且在进行字符比较时不用区分大小写。
答案
代码
#include <ctype.h> #define TRUE 1 #define FALSE 0 int palindrome(char *string) { char *start; char *end; start = string; end = string + strlen(string) - 1; while (TRUE) { while (start < end && !isalpha(*start)) start++; while (start < end && !isalpha(*end)) end--; if (start >= end) return TRUE; if (tolower(*start++) != tolower(*end--)) return FALSE; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
#
编程练习 11
编写一个程序,对标准输入进行扫描,并对单词“the”出现的次数进行计数。进行比较时应该区分大小写,所以“The”和“THE”并不计算在内。你可以认为各单词由一个或多个空格字符分隔,而且输入行在长度上不会超过100个字符。计数结果应该写到标准输出上。
答案
代码
#include <stdio.h> #include <string.h> #include <stdlib.h> #define SIZE 101 char const whitespace[] = " \n\r\t\v\f"; int main(void) { char buffer[SIZE]; char *token; int count; while (fgets(buffer, SIZE, stdin)) { for (token = strtok(buffer, whitespace); token != NULL; token = strtok(NULL, whitespace)) if (strcmp(token, "the") == 0) count++; } printf("%d\n", count); return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26输入
the one the two THE three the1
2
3
4输出
31
提示
- 注意
strstr查找的是子串,而不是单个的单词,如theater也会匹配the
#
编程练习 12

答案
代码
#include <string.h> #include <ctype.h> #define TRUE 1 #define FALSE 0 int prepare_key(char *key) { char *keyp; char *dup; int character; if (*key == '\0') return FALSE; for (keyp = key; *keyp != '\0'; keyp++) if (!isupper(*keyp)) { if (!islower(*keyp)) return FALSE; *keyp = toupper(*keyp); } for (keyp = key; *keyp != '\0'; keyp++) for (dup = keyp + 1; (dup = strchr(dup, *keyp)) != NULL;) strcpy(dup, dup + 1); /* ** Now add the remaining letters of the alphabet to the key. */ for (character = 'A'; character <= 'Z'; character++) if (strchr(key, character) == NULL) { *keyp = character; *++keyp == '\0'; } return TRUE; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
提示
- 最后要补全剩余的密钥,方便后续使用
#
编程练习 13
编写函数
void encrypt( char *data, char const *key );
它使用前题 prepare_key 函数所产生的密匙对 data 中的字符进行加密。 data 中的非字母字符不作修改,但字母字符则用密匙所提供的编过码的字符一一取代源字符。字母字符的大小写状态应该保留
答案
代码
#include <ctype.h> void encrypt(char *data, char const *key) { for (; *data != '\0'; data++) if (isalpha(*data)) if (isupper(*data)) *data = toupper(key[*data - 'A']); else *data = tolower(key[*data - 'a']); }1
2
3
4
5
6
7
8
9
10
11
#
编程练习 14
这个问题的最后部分就是编写函数
void decrypt( char *data, char const *key );
它接受一个加过密的字符串为参数,它的任务是重现原来的信息。除了它是用于解密之外,它的工作原理应该与 encrypt 相同。
答案
代码
#include <string.h> #include <ctype.h> void decrypt(char *data, char const *key) { for (; *data != '\0'; data++) if (isalpha(*data)) if (isupper(*data)) *data = strchr(key, *data) - key + 'A'; else *data = strchr(key, toupper(*data)) - key + 'a'; }1
2
3
4
5
6
7
8
9
10
11
12
#
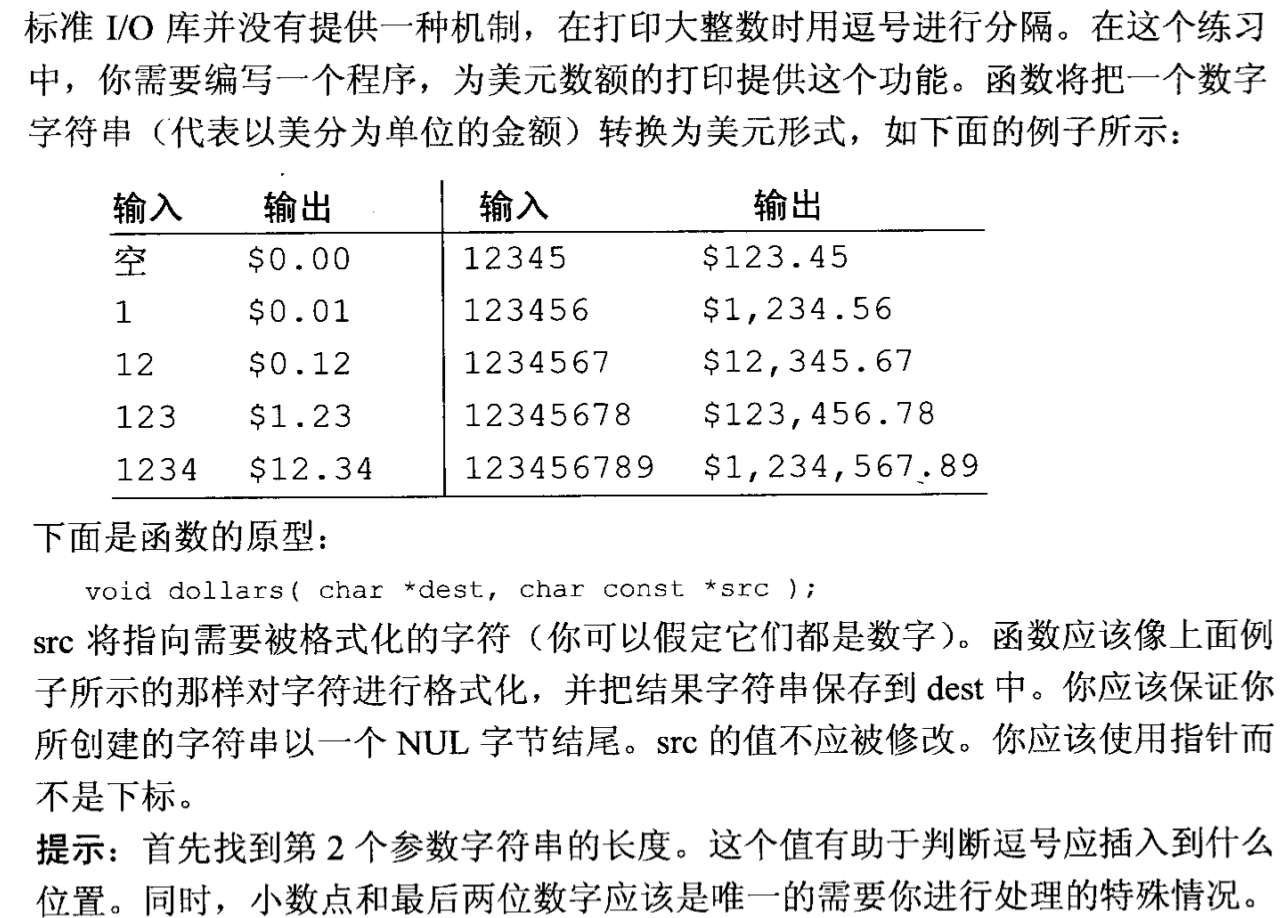
编程练习 15
答案
代码
#include <string.h> void dollars(char *dest, char const *src) { int length; int i; length = strlen(src); *dest++ = '$'; if (length > 2) for (i = length - 2; i > 0; i--) { *dest++ = *src++; if (i != 1 && i % 3 == 1) *dest++ = ','; } else *dest++ = '0'; *dest++ = '.'; *dest++ = length < 2 ? '0' : *src++; *dest++ = length < 1 ? '0' : *src++; *dest = '\0'; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#
编程练习 16

答案
代码
#include <ctype.h> #define TRUE 1 #define FALSE 0 int format(char *format_string, char const *digit_string) { int count; int point_flag; char *format_string_p; char const *digit_string_p; count = 0; point_flag = FALSE; if (digit_string == NULL || *digit_string == '\0') return FALSE; for (format_string_p = format_string; *format_string_p != '\0'; format_string_p++) { if (*format_string_p == '#') count++; if (*format_string_p == '.') point_flag = TRUE; } for (digit_string_p = digit_string; *digit_string_p != '\0'; digit_string_p++) if (isdigit(*digit_string_p)) count--; else return FALSE; while (format_string_p-- != format_string) { if (*format_string_p == '.') { point_flag = FALSE; continue; } if (digit_string_p != digit_string) { if (*format_string_p == ',') continue; *format_string_p = *--digit_string_p; } else { if (point_flag || *(format_string_p + 1) == '.') *format_string_p = '0'; else *format_string_p = ' '; } } if (count < 0) return FALSE; else return TRUE; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
#
编程练习 17
答案
代码
#include <stdio.h> char *edit(char *pattern, char const *digits) { char *signif = NULL; char fill_value; char pattern_ch; char digit_ch; if (pattern != NULL && digits != NULL) { fill_value = *pattern; while ((pattern_ch = *pattern) != '\0') { if (pattern_ch == '#') { digit_ch = *digits++; /* ** case 2 */ if (digit_ch == '\0') { *pattern = '\0'; return signif; } if (signif == NULL) { /* ** case 3 */ if (digit_ch == '0' || digit_ch == ' ') *pattern++ = fill_value; else { /* ** case 4 */ if (digit_ch == ' ') *pattern = '0'; else *pattern = digit_ch; signif = pattern++; } } else /* ** case 5 */ if (digit_ch == ' ') *pattern++ = '0'; else *pattern++ = digit_ch; } else if (pattern_ch == '!') { digit_ch = *digits++; if (digit_ch == '\0') { /* ** case 6 */ *pattern = '\0'; return signif; } if (signif == NULL) { /* ** case 7 */ if (digit_ch == ' ') *pattern = '0'; else *pattern = digit_ch; signif = pattern++; } else /* ** case 8 */ if (digit_ch == ' ') *pattern++ = '0'; else *pattern++ = digit_ch; } else { if (signif == NULL) /* ** case 9 */ *pattern++ = fill_value; else /* ** case 10 */ pattern++; } } return signif; } return NULL; /* case 1 */ }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
需要注意空格的处理