
 第 6 章 指针
第 6 章 指针
# 第 6 章 指针
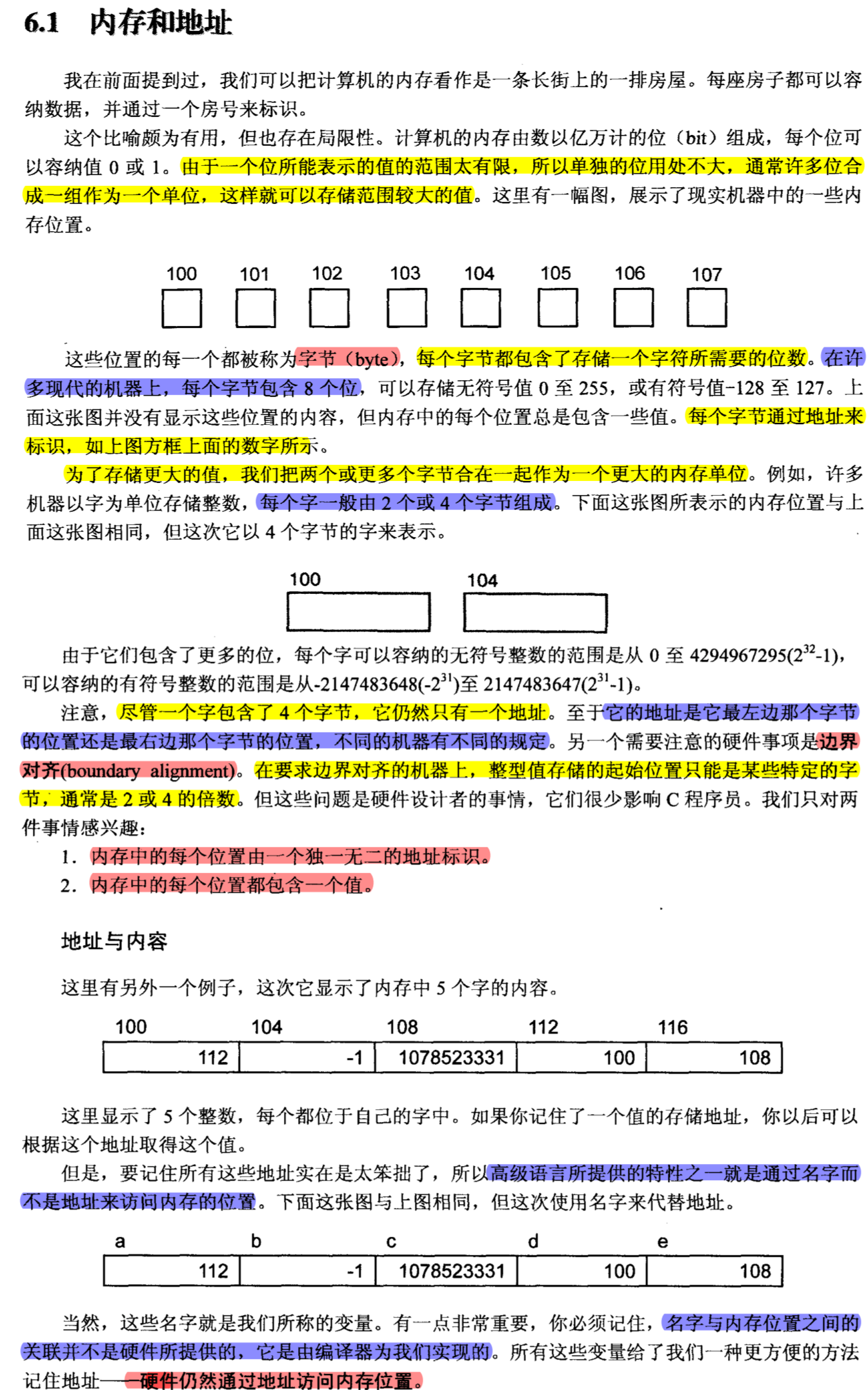
# 内存和地址
书本内容
# 值和类型
书本内容

# 指针变量的内容
书本内容

# 间接访问操作符
书本内容

# 未初始化和初始化的指针
书本内容

# NULL 指针
书本内容

# 指针,间接访问和左值
书本内容

# 指针,间接访问和变量
书本内容

# 指针常量
书本内容

笔记
*间接访问操作符只能作用于指针类型表达式
# 指针的指针
书本内容

# 指针表达式
书本内容

# 实例
书本内容

# 指针运算
书本内容
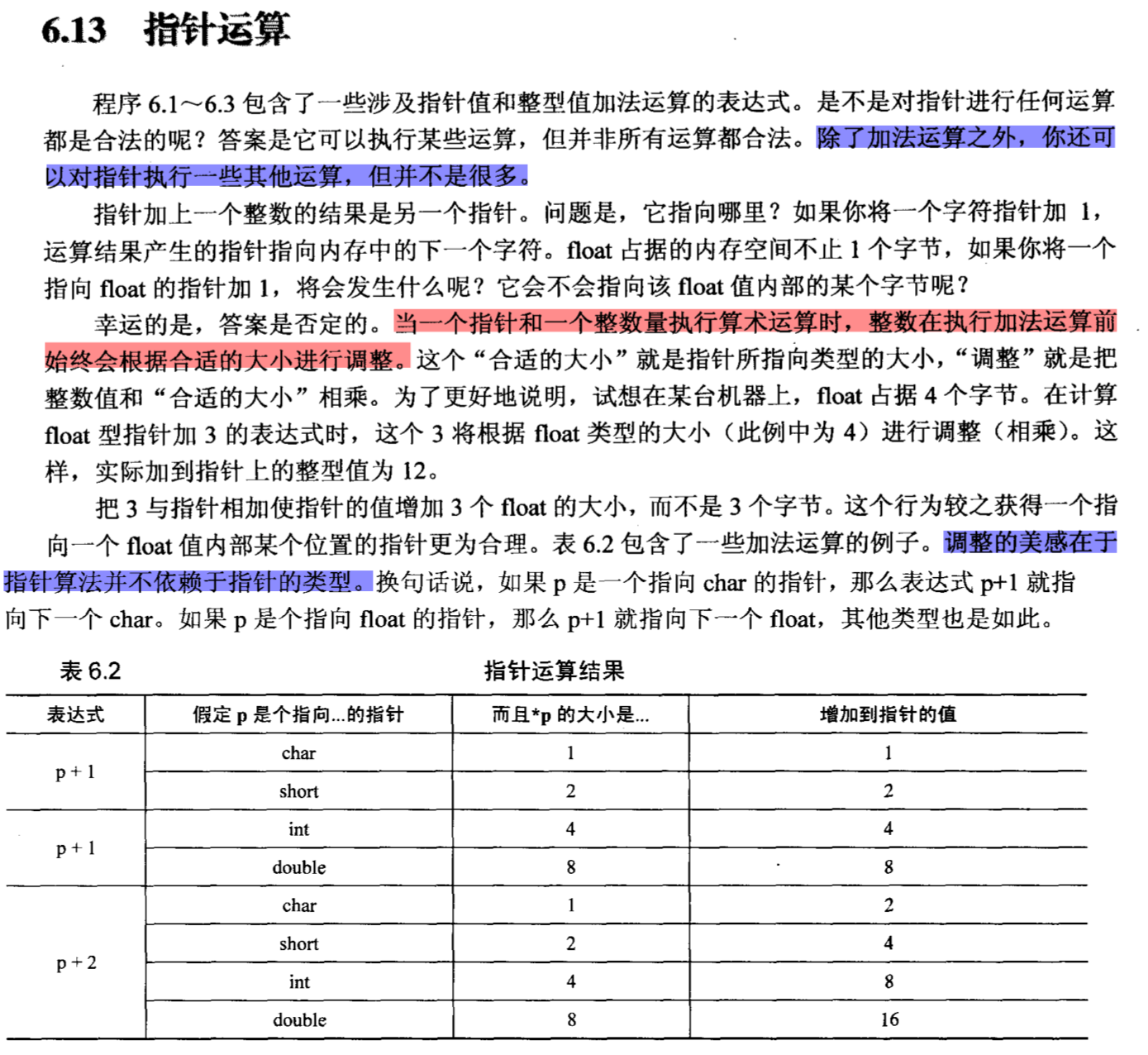
# 算术运算
书本内容
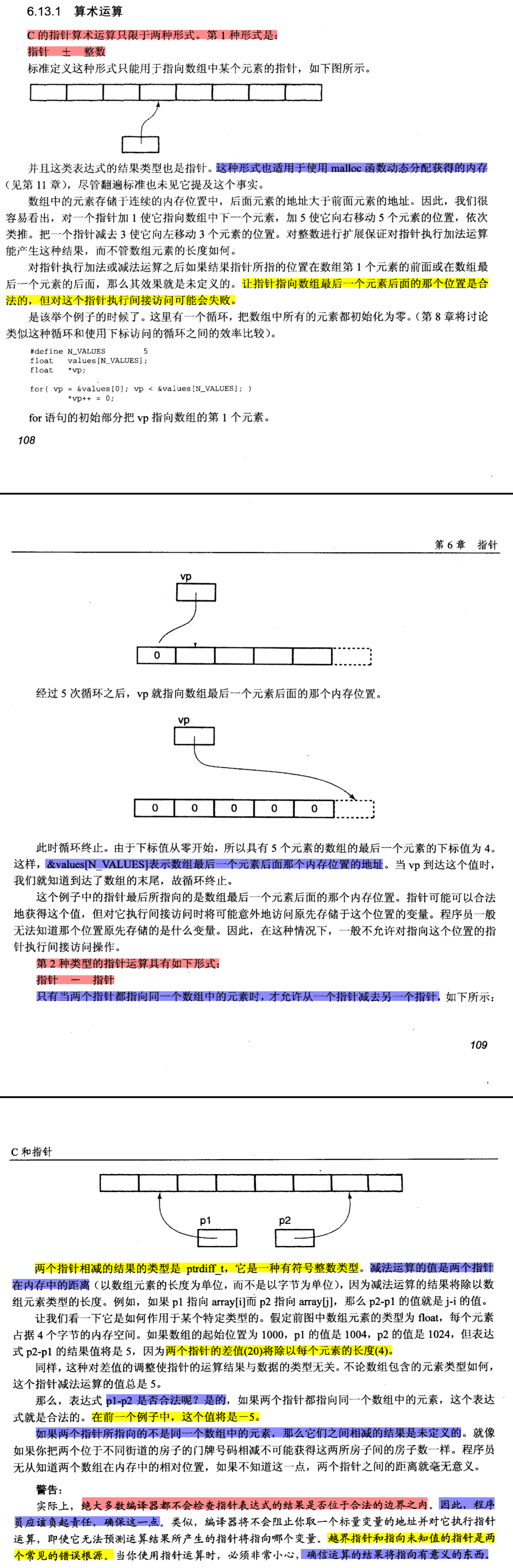
指针的算术运算只限于两种形式
- 指针
整数 - 指针
指针 - 两个指针相减的结果类型是一种有符号整数类型
其余形式的算术运算均是非法的
# 关系运算
书本内容

# 总结
书本内容

# 问题
#
问题 1
如果一个值的类型无法简单地通过观察它的位模式来判断,那么机器是如何知道应该怎样对这个值进行操纵的
答案
- 机器无法对值的类型进行判断
- 编译器根据值的声明类型创建适当的指令,机器只是盲目的执行这些指令
#
问题 2
C 为什么没有一种方法来声明字面值指针常量呢
答案
- 因为程序员无法提前得知编译器为变量分配的内存地址
#
问题 3
假定一个整数的值是 244。为什么机器不会把这个值解释为一个内存地址呢
答案
- 因为编译器会把
244解释为一个整数,而不是生成用于间接访问它的指令
#
问题 4
在有些机器上,编译器在内存位置零存储 0 这个值。对 NULL 指针进行解引用操作将访问这个位置。这种方法会产生什么后果
答案
- 这样是很危险的
- 因为标准并没有定义解引用一个
NULL指针的结果,所以其结果因编译器而异,程序不应该这样做 - 允许程序在进行这样的访问之后还能继续运行是很不幸的,因为这时程序很可能没有正常的运行
- 会给后续的调试带来很大的困难
#
问题 5
表达式(a)和(b)的求值过程有没有区别?如果有的话,区别在哪里?假定变量 offset 的值为 3
int i[ 10 ];
int *p = &i[ 0 ];
int offset;
p += offset; // (a)
p += 3; // (b)
2
3
4
5
6
答案
- 如果
offset的值为3,则 (a) (b) 表达式的结果是相同的 - 但是 (a) 表达式的耗时会超过 (b)
- 因为
offset的值在运行的过程中可能会发生变化,所以编译器不能提高预知offset的值- 因此 (a) 表达式会在程序运行的过程中需要计算
4 * offset(假设int占据 4 个字节) 的值
- 因此 (a) 表达式会在程序运行的过程中需要计算
- 对于 (b) 式而言,在编译的过程中,即可将
4 * 3加到p上,这样在运行的过程中便不必进行乘法操作
#
问题 6
下面的代码段有没有问题?如果有的话,问题在哪里
int array[ARRAY_SIZE];
int *pi;
for(pi = &array[0]; pi < &array[ARRAY_SIZE];)
*++pi = 0;
2
3
4
5
答案
- 由于指针在其被解引用前增值(前缀增值),因此会导致两个错误
- 数组的第 1 个元素并没有被清零
- 指针在越过数组边界后,仍然会进行解引用,会将其它某个内存地址的内容清零
提示
- 注意
pi在数组之后立即声明 - 如果编译器恰好把它放在紧跟数组后面的内存位置,结果将是灾难性的
- 当指针移到数组后面的那个内存位置时,那个最后被清零的内存位置就是保存指针的位置
- 这个指针(现在变成了零)因此仍然小于
&array[ARRAY_SIZE],所以循环将继续执行 - 指针在它被解引用之前增值,所以下一个被破坏的值就是存储于内存位置 4 的变量(假定整数的长度为4个字节)
- 如果硬件并没有捕捉到这个错误并终止程序,这个循环将快乐地继续下去,指针在内存中欢快地前行,破坏它遇见的所有值
- 当它再一次到达这个数组的位置时,就会重复上面这个过程,从而导致一个微妙的无限循环
#
问题 7
下面的表显示了几个内存位置的内容。每个位置由它的地址和存储于该位置的变量名标识。所有数字以十进制形式表示
使用这些值,用4种方法分别计算下面各个表达式的值。首先,假定所有的变量都是整型,找到表达式的右值,再找到它的左值,给出它所指定的内存位置的地址。接着,假定所有的变量都是指向整型的指针,重复上述步骤。注意:在执行地址运算时,假定整型和指针的长度都是4个字节
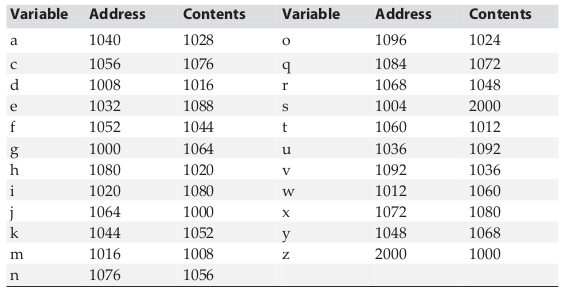
答案
| 序号 | 表达式 | 整型 右值 | 整型 左值地址 | 整型指针 右值 | 整型指针 左值地址 |
|---|---|---|---|---|---|
| a. | m | 1008 | 1016 | 1008 | 1016 |
| b. | v + 1 | 1037 | illegal | 1040 | illegal |
| c. | j - 4 | 996 | illegal | 984 | illegal |
| d. | a - d | 12 | illegal | 3 | illegal |
| e. | v - w | -24 | illegal | -6 | illegal |
| f. | &c | 1056 | illegal | 1056 | illegal |
| g. | &e + 1 | 1036 | illegal | 1036 | illegal |
| h. | &o - 4 | 1080 | illegal | 1080 | illegal |
| i. | &(f + 2) | illegal | illegal | illegal | illegal |
| j. | *g | illegal | illegal | 1000 | 1064 |
| k. | *k + 1 | illegal | illegal | 1045 | illegal |
| l. | *(n + 1) | illegal | illegal | 1012 | 1060 |
| m. | *h - 4 | illegal | illegal | 1076 | illegal |
| n. | *(u - 4) | illegal | illegal | 1056 | 1076 |
| o. | *f - g | illegal | illegal | illegal | illegal |
| p. | *f - *g | illegal | illegal | 52 | illegal |
| q. | *s - *q | illegal | illegal | -80 | illegal |
| r. | *(r - t) | illegal | illegal | illegal | illegal |
| s. | y > i | 0 | illegal | 0 | illegal |
| t. | y > *i | illegal | illegal | illegal | illegal |
| u. | *y > *i | illegal | illegal | 1 | illegal |
| v. | **h | illegal | illegal | illegal | illegal |
| w. | c++ | 1076 | illegal | 1076 | illegal |
| x. | ++c | 1077 | illegal | 1080 | illegal |
| y. | *q++ | illegal | illegal | 1080 | 1072 |
| z. | (*q)++ | illegal | illegal | 1080 | illegal |
| aa. | *++q | illegal | illegal | 1056 | 1076 |
| bb. | ++*q | illegal | illegal | 1081 | illegal |
| cc. | *++*q | illegal | illegal | illegal | illegal |
| dd. | ++*(*q)++ | illegal | illegal | illegal | illegal |
# 编程练习
#
编程练习 1
请编写一个函数,它在一个字符串中进行搜索,查找所有在一个给定字符集合中出现的字符。这个函数的原型应该如下
char *find_char( char const *source, char const *chars );
它的基本想法是查找 source 字符串中匹配 chars 字符串中任何字符的第 1 个字符,函数然后返回一个指向 source 中第 1 个匹配所找到的位置的指针。如果 source 中的所有字符均不匹配 chars 中的任何字符,函数就返回一个 NULL 指针。如果任何一个参数为 NULL ,或任何一个参数所指向的字符串为空,函数也返回一个 NULL 指针。
举个例子,假定 source 指向 ABCDEF 。如果 chars 指向 XYZ 、 JURY 或 QQQQ ,函数就返回一个 NULL 指针。如果 chars 指向 XRCQEF ,函数就返回一个指向 source 中 C 字符的指针。参数所指向的字符串是绝不会被修改的
碰巧, C 函数库中存在一个名叫 strpbrk 的函数,它的功能几乎和这个你要编写的函数一模一样。但这个程序的目的是让你自己练习操纵指针,所以:
a .你不应该使用任何用于操纵字符串的库函数(如 strcpy, strcmp, index 等)
b .函数中的任何地方都不应该使用下标引用
答案
代码
/* ** Find the first occurrence in 'source' of any of the characters in 'chars' and ** return a pointer to that location. If none are found, or if 'source' or 'chars' ** are NULL pointers, a NULL pointer is returned. */ #include <limits.h> #define NULL 0 char *find_char(char const *source, char const *chars) { char char_map[1 << CHAR_BIT] = {0}; /* ** Verify the input */ if (source == NULL || chars == NULL || *source == '\0' || *chars == '\0') return NULL; /* ** Look through `source` for a match with the character in `chars` */ while (*chars != '\0') char_map[*chars++] = 1; while (*source != '\0') if (char_map[*source++]) return (char *)(source - 1); return NULL; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#
编程练习 2
请编写一个函数,删除一个字符串的一部分。函数的原型如下:
int del_substr(char *str, char const *substr);
函数首先应该判断 substr 是否出现在 str 中。如果它并未出现,函数就返回 0 ;如果出现,函数应该把 str 中位于该子串后面的所有字符复制到该子串的位置,从而删除这个子串,然后函数返回 1 。如果 substr 多次出现在 str 中,函数只删除第 1 次出现的子串。函数的第 2 个参数绝不会被修改
举个例子,假定 str 指向 ABCDEFG 。如果 substr 指向 FGH 、 CDF 或 XABC ,函数应该返回 0 , str 未作任何修改。但如果 substr 指向 CDE ,函数就把 str 修改为指向 ABFG ,方法是把 F 、 G 和结尾的 NUL 字节复制到 C 的位置,然后函数返回 1 。不论出现什么情况,函数的第 2 个参数都不应该被修改
和上题的程序一样:
a.你不应该使用任何用于操纵字符串的库函数(如 strcpy, strcmp ,等)。
b.函数中的任何地方都不应该使用下标引用。
一个值得注意的是,空字符串是每个字符串的一个子串,在字符串中删除一个空子串字符串不会产生变化
答案
代码
/* ** If the string "substr" appears in "str", delete it. */ #define NULL 0 #define TRUE 1 #define FALSE 0 /* ** See if the substring beginning at "str" matches the string "want". If ** so, return a pointer to the first character in "str" after the match. */ char *match(char *str, char const *want) { while (*want != '\0') if (*str++ != *want++) return NULL; return str; } int del_substr(char *str, char const *substr) { char *next; while (*str != '\0') { next = match(str, substr); if (next != NULL) { /* ** Delete the substring by copying the bytes after it over the bytes of ** the substring itself. */ while (*str++ = *next++) ; return TRUE; } str++; } return FALSE; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#
编程练习 3
编写函数 reverse_string,它的原型如下
void reverse_string( char *string );
函数把参数字符串中的字符反向排列。请使用指针而不是数组下标,不要使用任何C函数库中用于操纵字符串的函数。提示:不需要声明一个局部数组来临时存储参数字符串
答案
代码
/* ** Reverse the string contained in the argument */ void swap(char *str1, char *str2) { *str1 ^= *str2; *str2 ^= *str1; *str1 ^= *str2; } void reverse_string(char *string) { char *tail; for (tail = string; *tail != '\0'; tail++) ; tail--; while (string < tail) swap(string++, tail--); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
提示
- 头指针和尾指针同时向中间靠扰,可以简化整个程序的逻辑
- 可以用异或运算来快速的交换两个整型变量
a ^=b; b ^= a; a ^= b
#
编程练习 4
质数就是只能被1和本身整除的整数。Eratosthenes筛选法是一种计算质数的有效方法。这个算法的第1步就是写下所有从2至某个上限之间的所有整数。在算法的剩余部分,你遍历整个列表并剔除所有不是质数的整数。
后面的步骤是这样的。找到列表中的第1个不被剔除的数(也就是2),然后将列表后面所有逢双的数都剔除,因为它们都可以被2整除,因此不是质数。接着,再回到列表的头部重新开始,此时列表中尚未被剔除的第1个数是3,所以在3之后把每逢第3个数(3的倍数)剔除。完成这一步之后,再回到列表开头,3后面的下一个数是4,但它是2的倍数,已经被剔除,所以将其跳过,轮到5,将所有5的倍数剔除。这样依次类推、反复进行,最后列表中未被剔除的数均为质数
编写一个程序,实现这个算法,使用数组表示你的列表。每个数组元素的值用于标记对应的数是否已被剔除。开始时数组所有元素的值都设置为TRUE,当算法要求“剔除”其对应的数时,就把这个元素设置为FALSE。如果你的程序运行于16位的机器上,小心考虑是不是需要把某个变量声明为long。一开始先使用包含1000个元素的数组。如果你使用字符数组,使用相同的空间,你将会比使用整数数组找到更多的质数。你可以使用下标来表示指向数组首元素和尾元素的指针,但你应该使用指针来访问数组元素。
注意除了2之外,所有的偶数都不是质数。稍微多想一下,你可以使程序的空间效率大为提高,方法是数组中的元素只对应奇数。这样,在相同的数组空间内,你可以寻找到的质数的个数大约是原先的两倍。
答案
代码
/* ** Sieve of Eratosthenes -- compute prime numbers using an array. */ #include <stdio.h> #include <stdlib.h> #define SIZE 1000 #define TRUE 1 #define FALSE 0 int main(void) { char sieve[SIZE]; int number; char *sp; /*pointer to access the sieve*/ for (sp = sieve; sp < &sieve[SIZE]; sp++) *sp = TRUE; printf("2\n"); for (number = 3;; number += 2) { sp = sieve + (number - 3) / 2; if (sp >= &sieve[SIZE]) break; if (*sp) { printf("%d\n", number); while ((sp += number) < &sieve[SIZE]) *sp = FALSE; } } return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
提示
- 注意
char sieve[SIZE] = {1}并不能将数组全部初始化为1 - 剔除所有的偶数后,偶数倍也相应的被剔除,只用考虑奇数倍的情况,需要注意其下标转换的推导
#
编程练习 5
修改前一题的Eratosthenes程序,使用位的数组而不是字符数组,这里要用到第5章编程练习中所开发的位数组函数。这个修改使程序的空间效率进一步提高,不过代价是时间效率降低。在你的系统中,使用这个方法,你所能找到的最大质数是多少?
答案
代码
#include <stdio.h> #include <stdlib.h> #include <limits.h> #include "bitarray.h" /* ** MAX_VALUE is the max value in the "list" ** MAX_BIT_NUMBER is the bit number corresponding to MAX_VALUE, considering ** that only keep bits to represent the odd numbers starting with 3. ** SIZE is the number of characters needed to get enough bits. */ #define MAX_VALUE 1000 #define MAX_BIT_NUMBER ((MAX_VALUE - 3) / 2) #define SIZE (MAX_BIT_NUMBER / CHAR_BIT + 1) int main(void) { char sieve[SIZE]; int number; int bit_number; char *sp; for (sp = sieve; sp < &sieve[SIZE]; sp++) *sp = ~0; printf("2\n"); for (number = 3; number < MAX_VALUE; number += 2) { bit_number = (number - 3) / 2; if (test_bit(sieve, bit_number)) { printf("%d\n", number); while ((bit_number += number) <= MAX_BIT_NUMBER) clear_bit(sieve, bit_number); } } return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39bitarray.h的代码如下
void set_bit(char bit_array[], unsigned bit_number); void clear_bit(char bit_array[], unsigned bit_number); void assign_bit(char bit_array[], unsigned bit_number, int value); int test_bit(char bit_array[], unsigned bit_number);1
2
3
4
5
6
7由于程序中用数组
sieve来储存值,其会储存到堆栈上,所以其大小要受到堆栈大小的限制Ubuntu 可以通过
ulimit -a来获取运行时堆栈的大小,如下可得堆栈的限制为 8192 kb❯ ulimit -a -t: cpu time (seconds) unlimited -f: file size (blocks) unlimited -d: data seg size (kbytes) unlimited -s: stack size (kbytes) 8192 -c: core file size (blocks) 0 -m: resident set size (kbytes) unlimited -u: processes 127618 -n: file descriptors 8192 -l: locked-in-memory size (kbytes) 65536 -v: address space (kbytes) unlimited -x: file locks unlimited -i: pending signals 127618 -q: bytes in POSIX msg queues 819200 -e: max nice 0 -r: max rt priority 0 -N 15: unlimited1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在程序中,1 位数相当于用
0.5个bit来储存(偶数被排除在外)- 可以计算得到的最大整数为
- 由于堆栈还要储存其它内容,因此实际可以计算的最大素数的值要比
134, 217, 728要小
- 可以计算得到的最大整数为
#
编程练习 6
大质数是不是和小质数一样多?换句话说,在50 000和51 000之间的质数是不是和1 000 000和1 001 000之间的质数一样多?使用前面的程序计算0到1 000之间有多少个质数?1 000到2 000之间有多少个质数?以此每隔1 000类推,到1 000 000(或是你的机器上允许的最大正整数)有多少个质数?每隔1 000个数中质数的数量呈什么趋势?
答案
数学上的理论是 素数定理
- 对
求二阶导数即可得到本题的结论
- 对
间隔为
1000时结果不明显,将间隔改为10, 000, 000, 计算到100, 000, 000为止代码
#include <stdio.h> #include <stdlib.h> #include <limits.h> #include "bitarray.h" /* ** MAX_VALUE is the max value in the "list" ** MAX_BIT_NUMBER is the bit number corresponding to MAX_VALUE, considering ** that only keep bits to represent the odd numbers starting with 3. ** SIZE is the number of characters needed to get enough bits. */ #define MAX_VALUE 100000000 #define MAX_BIT_NUMBER ((MAX_VALUE - 3) / 2) #define SIZE (MAX_BIT_NUMBER / CHAR_BIT + 1) int main(void) { char sieve[SIZE]; int number; int bit_number; char *sp; for (sp = sieve; sp < &sieve[SIZE]; sp++) *sp = ~0; for (number = 3; number < MAX_VALUE; number += 2) { bit_number = (number - 3) / 2; if (test_bit(sieve, bit_number)) { while ((bit_number += number) <= MAX_BIT_NUMBER) clear_bit(sieve, bit_number); } } int step = MAX_VALUE / 10; int count; int interval_num = 1; float count_per_thousand; printf("Range of Numbers Average # of Primes per Thousand Numbers\n"); count = 1; for (number = 3; number < MAX_VALUE; number += 2) { bit_number = (number - 3) / 2; if (number > interval_num * step) { count_per_thousand = count / (step / 1000.0); printf("%10d -- %10d: %10.3f\n", (interval_num - 1) * step, interval_num * step, count_per_thousand); interval_num++; count = 0; } if (test_bit(sieve, bit_number)) count++; } count_per_thousand = count / (step / 1000.0); printf("%10d -- %10d: %10.3f\n", (interval_num - 1) * step, interval_num * step, count_per_thousand); return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61输出
Range of Numbers Average # of Primes per Thousand Numbers
0 -- 10000000: 66.458
10000000 -- 20000000: 60.603
20000000 -- 30000000: 58.725
30000000 -- 40000000: 57.579
40000000 -- 50000000: 56.748
50000000 -- 60000000: 56.098
60000000 -- 70000000: 55.595
70000000 -- 80000000: 55.132
80000000 -- 90000000: 54.757
90000000 -- 100000000: 54.450
2
3
4
5
6
7
8
9
10
11
- 从结果可以看出,平均每 1000 个数中质数的数量随着数字的增大,呈现下降的趋势