
 第 5 章 操作符和表达式
第 5 章 操作符和表达式
# 操作符和表达式
主要内容
C 提供了所有你希望编程语言应该拥有的操作符
- 它甚至提供了一些你意想不到的操作符
- 事实上, C 被许多人所诉病的一个缺点就是它品种繁多的操作符
- C 的这个特点使它很难精通
- 但另一方面, C 的许多操作符具有其他语言的操作符无可抗衡的价值
- 这也是 C 适用千开发范围极广的应用程序的原因之一
在介绍完操作符之后,将讨论表达式求值的规则,包括操作符优先级和算术转换。
书本内容

# 操作符
书本内容

# 算术操作符
书本内容

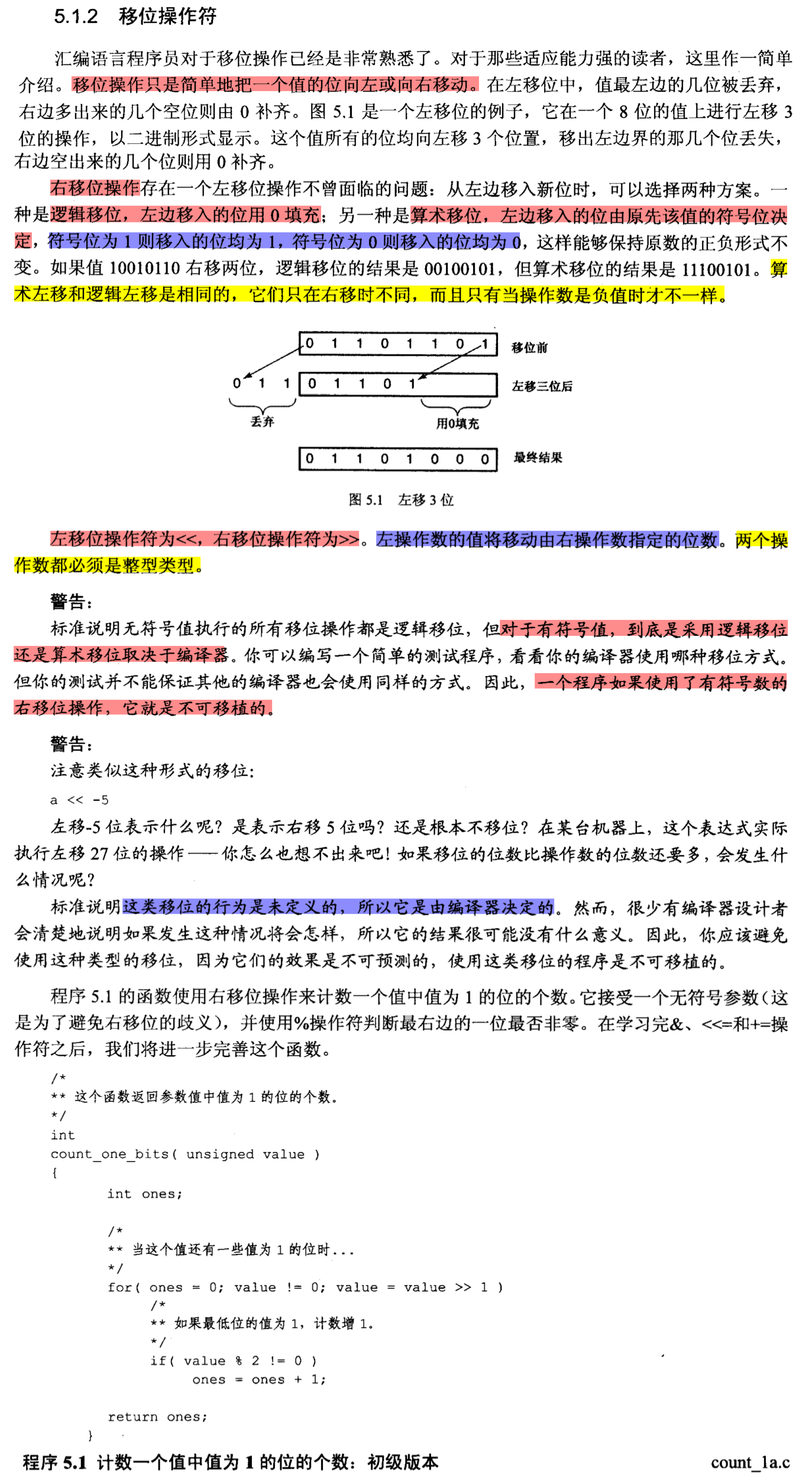
# 移位操作符
书本内容
# 位操作符
书本内容

笔记
- 标准说明无符号数所有的移位操作均为逻辑移位
# 赋值
书本内容

EOF
EOF在stdio.h中按如下语句定义,其字面值的默认类型为int#define EOF (-1)1-
- Linux 下为
Ctrl + D, Windows 下为Ctrl + Z - 可能要输入
Enter才会生效
- Linux 下为
getchar()的返回值为int- 当其读入
EOF后,返回值为-1 - 如果
int有 32 位,则-1的十六进制为0xFFFF FFFF
- 当其读入
对于下列语句
char ch; ... while ((ch = getchar()) != EOF)...1
2
3char用八位二进制储存- 当
char为signed char时,当读入字符\377(0xFF)时,ch=0xFF- 其与
EOF进行比较时,ch会被提升为int,有符号的提升会保留符号位的1, 因此0xFF会被提升为0x FFFF FFFF - 此时满足判断条件,与程序的本意不符
- 其与
- 当
char为unsigned char时, 当读入EOF时,getchar()返回0xFFFF FFFF(-1),其会被截短为0xFF,ch=0xFF- 当与
EOF(-1)进行比较时,ch被提升为int, 无符号提升时直接在左边添0, 结果为0x0000 00FF,其不与EOF相同,结果就是造成死循环
- 当与
# 单目操作符
书本内容

#
& 取地址操作符
# 关系操作符
书本内容

# 逻辑操作符
书本内容

# 条件操作符
书本内容

# 逗号操作符
书本内容

# 下标引用, 函数调用和结构成员
书本内容

# 布尔值
书本内容

# 表达式求值
书本内容

# 隐式类型转换
书本内容

# 算术转换
书本内容

# 操作符的属性 -- 优先级及结合性
书本内容
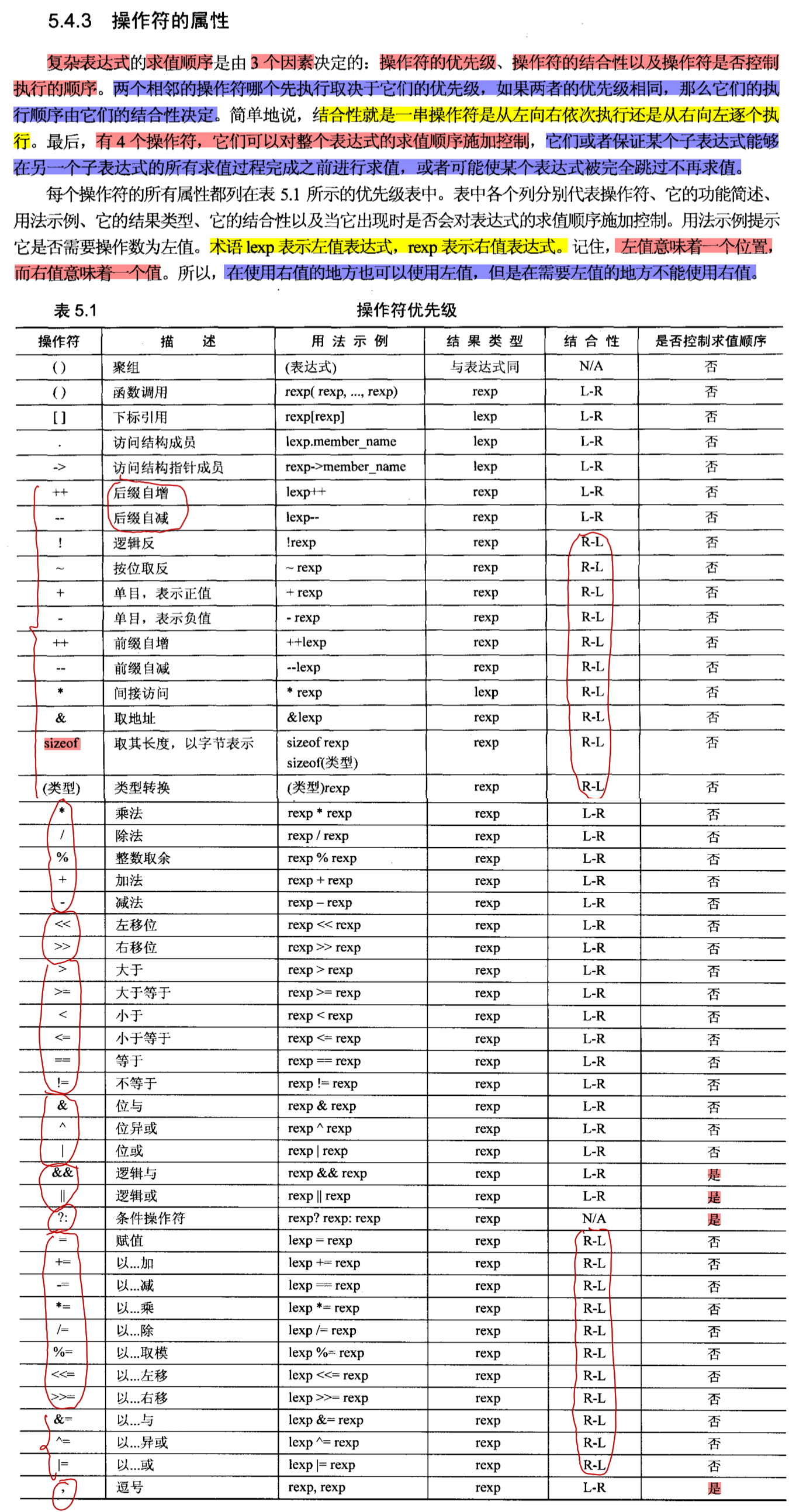
按操作符类别大致的划分优先级
聚组 >
函数调用 > 下标引用 > 结构成员访问 >
单目操作符 >
算术操作符 > 移位操作符 >
关系操作符 > 位操作符 > 逻辑操作符 > 条件操作符 >
赋值操作符 >
逗号操作符
注意
- 对于关系运算符
>>>=><><=>==>!=
- 对于位运算符
&>^(位异或) >|
- 对于逻辑操作符
&&的优先级要大于||
- 自增
++与自减--操作符- 后缀形式的优先级要大于前缀形式
结果类型为左值的操作符
[]下标引用rexp[rexp]
.访问结构体成员lexp.member_name
->访问结构指针成员rexp.member_name
*间接访问*rexp
()可能产生左值- 如
(*rexp)产生的为左值 - 而
(rexp)却为右值
- 如
用于前缀操作的单目操作符和各种赋值操作符的结合顺序为从右向左
- 其余均为从左向右
# 优先级和求值的顺序
书本内容

逻辑操作符的求值顺序问题
- 对于表达式
if (x < 100 || x > 200 && x != y)- 由于
&&的优先级比||高, 所以表达式等价于if (x < 100 || (x > 200 && x != y)) - 但是如果
x < 100成立,则不再对(x > 200 && x != y)进行判断,符合||运算符的短路求解原则 - ⌛tag+todo 补上编译原理中的翻译过程
- ⌛tag+todo 查标准中关于此处的定义
- 由于
# 总结
书本内容

# 问题
#
问题 1
下面这个表达式的类型和值分别是什么?
(float)(25/10)
答案
- 类型为
float - 值为
2.0
#
问题 2
下面这个程序的结果是什么?
int
func( void )
{
static int counter = 1;
return ++counter;
}
int
main()
{
int answer;
answer = func() - func() * func();
printf( "%d\n", answer );
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
答案
clang-12 和 gcc 9.3.0 输出的结果均为
-10但最后的结果却因编辑器而异,因为标准只规定了乘法运算必须在加法运算前完成,但并没有规定函数调用的顺序,因此,以下几种结果,都是合法的
合法结果
-10 ( 2 - 3 * 4 or 2 - 4 * 3)
-5 ( 3 - 2 * 4 or 3 - 4 * 2)
-2 ( 4 - 2 * 3 or 4 - 2 * 3)
2
3
#
#
问题 4
条件操作符在运行时较之if语句是更快还是更慢?试比较下面两个代码段。
if( a > 3 )
i = b + 1;
else
i = c * 5;
2
3
4
i = a > 3 ? b + 1 : c *5;
答案
- 两者在速度上并无区别,因为其执行的过程是一致的
#
问题 5
可以被 4 整除的年份是闰年,但是其中能够被 100 整除的年份又不是闰年。但是,这其中能够被 400 整除的年份又是闰年。请用一条赋值语句,如果变量 year 的值是闰年,把变量 leap_year 设置为真。如果 year 的值不是闰年,把 leap_year 设置为假
答案
leap_year = year % 400 == 0 ||
year % 4 == 0 && year % 100 != 0
2
提示
&&的优先级比||高
#
问题 6
哪些操作符具有副作用?它们具有什么副作用?
答案
- 函数调用
()- 可能会产生副作用
- 单目运算符中的
++和--- 其前缀和后缀形式均会修改操作数的值
- 赋值运算符
- 包括
=和所有的复合赋值符 - 其会修改作为左值的操作数的值
- 包括
#
问题 7
下面这个代码段的结果是什么?
int a = 20;
...
if( 1 <= a <= 10 )
printf( "In range\n" );
else
printf( "Out of range\n" );
2
3
4
5
6
答案
- 会输出
In range - 因为
<=为关系操作符,其结合性是从左至右的- 当
a = 20时,1 <= 20的结果是1, 然后1 <= 10的结果也是1, 即1 <= 20 <=10的结果为1, 为true
- 当
1 <= a <= 10是合法语句,但是却不能像预期的那样的工作
在 Python 中按照这种写法,可以达至预期的结果
a = 20
if 1 <= a <= 10:
print("In range\n");
else:
print("Out of range\n")
2
3
4
5
- 其会输出
Out of range.
#
问题 8
改写下面的代码段,消除多余的代码。
a = f1( x );
b = f2( x + a );
for( c = f3( a, b ); c > 0; c = f3( a, b ) ){
statements
a = f1( ++x );
b = f2( x + a );
}
2
3
4
5
6
7
答案
- 使用逗号表达式改写
for(a = f1(x);
b = f2(x + a), c = f3(a, b), c > 0;
a = f1(++x))
{
statements
}
2
3
4
5
6
#
问题 9
下面的循环能够实现它的目的吗?
non_zero = 0;
for( i = 0; i < ARRAY_SIZE; i += 1 )
non_zero += array[i];
if( !non_zero )
printf( "Values are all zero\n" );
else
printf( "There are nonzero values\n" );
2
3
4
5
6
7
答案
- 不能,因为不知道
non_zero的类型- 如果其为有符号数
signed整数,则可能出现正负非零值相加等于0的情况
- 如果其为有符号数
#
问题 10
根据下面的变量声明和初始化,计算下列每个表达式的值。如果某个表达式具有 副作用(也就是说它修改了一个或多个变量的值),注明它们。在计算每个表达式时,每个变量所使用的是开始时给出的初始值,而不是前一个表达式的结果
int a = 10, b = -25;
int c = 0, d = 3;
int e = 20;
2
3
a. b
b. b++
c. –a
d. a / 6
e. a % 6
f. b % 10
g. a << 2
h. b >> 3
i. a > b
j. b = a
k. b == a
l. a & b
m. a ^ b
n. a | b
o. ~b
p. c && a
q. c || a
r. b ? a : c
s. a += 2
t. b &= 20
u. b >>= 3
v. a %= 6
w. d = a > b
x. a = b = c = d
y. e = d + ( c = a + b ) + c
z. a + b * 3
aa. b >> a – 4
bb. a != b != c
cc. a == b == c
dd. d < a < e
ee. e > a > d
ff. a – 10 > b + 10
gg. a & 0x1 == b & 0x1
hh. a | b << a & b
ii. a > c || ++a > b
jj. a > c && ++a > b
kk. ! ~ b++
ll. b++ & a <= 30
mm. a – b, c += d, e – c
nn. a >>= 3 > 0
oo. a <<= d > 20 ? b && c++ : d—
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
答案
a. b // -25
b. b++ // -25 b = -24
c. --a // 9, c = 9
d. a / 6 // 1
e. a % 6 // 4
f. b % 10 // -5
g. a << 2 // 40
h. b >> 3 // -4
i. a > b // 1
j. b = a // 10, b = 10
k. b == a // 0
l. a & b // 2
m. a ^ b // -19
n. a | b // -17
o. ~b // 24
p. c && a // 0
q. c || a // 1
r. b ? a : c // 10
s. a += 2 // 12, a = 12
t. b &= 20 // 4, b = 4
u. b >>= 3 // -4, b = -4
v. a %= 6 // 4, a = 4
w. d = a > b // 1, d = 1
x. a = b = c = d // 3, a = 3, b = 3, c = 3
y. e = d + ( c = a + b ) + c // -27, c = -15, e = -27
z. a + b * 3 // -65
aa. b >> a – 4 // -1
bb. a != b != c // 1
cc. a == b == c // 1
dd. d < a < e // 1
ee. e > a > d // 0
ff. a – 10 > b + 10 // 1
gg. a & 0x1 == b & 0x1 // 0
hh. a | b << a & b // -25590
ii. a > c || ++a > b // 1
jj. a > c && ++a > b // 1, a = 11
kk. ! ~ b++ // 0, b = -24
ll. b++ & a <= 30 // 1, b = -24
mm. a – b, c += d, e – c // 17, c = 3
nn. a >>= 3 > 0 // 5, a = 5
oo. a <<= d > 20 ? b && c++ : d-- // 80, d = 2, a = 80
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#
问题 11
下面列出了几个表达式。请判断编译器是如何对各个表达式进行求值的,并在不改变求值顺序的情况下,尽可能去除多余的括号
a. a + ( b / c )
b. ( a + b ) / c
c. ( a * b ) % 6
d. a * ( b % 6 )
e. ( a + b ) == 6
f. !( ( a >= '0' ) && ( a <= '9' ) )
g. ( ( a & 0x2f ) == ( b | 1 ) ) && ( ( ~ c ) > 0 )
h. ( ( a << b ) – 3 ) < ( b << ( a + 3 ) )
i. ~ ( a ++ )
j. ((a == 2) || (a == 4)) && ((b == 2) || (b == 4))
k. ( a & b ) ^ ( a | b )
l. ( a + ( b + c ) )
2
3
4
5
6
7
8
9
10
11
12
答案
a. a + ( b / c )
// a + b / c
b. ( a + b ) / c
// (a + b) / c
c. ( a * b ) % 6
// a * b % 6
d. a * ( b % 6 )
// a * (b % 6)
e. ( a + b ) == 6
// a + b == 6
f. !( ( a >= '0' ) && ( a <= '9' ) )
// !(a >= '0' && a <= '9' )
g. ( ( a & 0x2f ) == ( b | 1 ) ) && ( ( ~ c ) > 0 )
// (a & 0x2f) == (b|1) && ~ c > 0
h. ( ( a << b ) – 3 ) < ( b << ( a + 3 ) )
// (a << b) - 3 < b << a + 3
i. ~ ( a ++ )
// ~a++
j. ((a == 2) || (a == 4)) && ((b == 2) || (b == 4))
// (a == 2 || a == 4) && (b == 2 || b == 4)
k. ( a & b ) ^ ( a | b )
// a & b ^ (a | b)
l. ( a + ( b + c ) )
// a + (b + c)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#
问题 12
如何判断在你的机器上对一个有符号值进行右移位操作时执行的是算术移位还是逻辑移位?
答案
在补码机中,定义一个
singed int类型,将其右移一位,如果结果为负数,说明是算术移位;如果结果为正数,说明为逻辑移位代码
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int a = -1;
if (a >> 1 < 0)
printf("Arithmetic shit\n");
else
printf("Logical shit\n");
return EXIT_SUCCESS;
}
2
3
4
5
6
7
8
9
10
11
12
- 输出
Arithmetic shit
- 编译器版本
❯ cc --version
Ubuntu clang version 12.0.0-3ubuntu1~20.04.3
Target: x86_64-pc-linux-gnu
Thread model: posix
InstalledDir: /usr/bin
2
3
4
5
# 编程练习
#
编程练习 1
编写一个程序,从标准输入读取字符,并把它们写到标准输出中。除了大写字母字符要转换为小写字母之外,所有字符的输出形式应该和它的输入形式完全相同
答案
- 代码
/*
** Copy the standard input to the standard output, converting
** all uppercase characters to lowercase.
*/
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int ch;
while ((ch = getchar()) != EOF)
{
if (ch >= 'A' && ch <= 'Z')
ch += 'a' - 'A'; // The ASCII code of a is greater than A
putchar(ch);
}
return EXIT_SUCCESS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
- 输入
-=-. Simple is better than complex.
- 输出
-=-. simple is better than complex.
2
#
编程练习 2
编写一个程序,从标准输入读取字符,并把它们写到标准输出中。所有非字母字符都完全按照它的输入形式输出,字母字符在输出前进行加密
- 加密方法很简单:每个字母被修改为在字母表上距其
13个位置(前或后)的字母。例如,A被修改为N,B被修改为O,Z被修改为M,以此类推。注意大小写字母都应该被转换。提示:记住字符实际上是一个较小的整型值这一点可能对你有所帮助
答案
- 代码
/*
** Encrypt the text on the standard input by rotating the alphabetic characters
** 13 positions through the alphabet. (Note: this program decrypts as well.)
*/
#include <stdio.h>
#include <stdlib.h>
/*
** Encrypt a single character. The base argument is either an upper or
** lower case A, depending on the case of the ch argument.
*/
int encrypt(int ch, int base)
{
return (ch - base + 13) % 26 + base;
}
int main(void)
{
int ch;
while ((ch = getchar()) != EOF)
{
if (ch >= 'A' && ch <= 'Z')
ch = encrypt(ch, 'A');
else if (ch >= 'a' && ch <= 'z')
ch = encrypt(ch, 'a');
putchar(ch);
}
return EXIT_SUCCESS;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
- 输入
I'm ABZ, who are you?
- 输出
V'z NOM, jub ner lbh?
2
#
编程练习 3
请编写函数
unsigned int reverse_bits( unsigned int value );
这个函数的返回值是把
value的二进制位模式从左到右变换一下后的值。例如,在32位机器上,25这个值包含下列各个位000000000000000000000000000110011函数的返回值应该是
2 550 136 832,它的二进制位模式是100110000000000000000000000000001
答案
- 代码
/*
** Reverse the order of the bits in an unsigned integer value.
*/
unsigned int reverse_bits(unsigned int value)
{
unsigned int result;
result = 0;
/*
** Keep going as long as i is nonzero. This makes the loop
** independent of the machine's word size, hence portable.
*/
for (unsigned int i = 1; i != 0; i <<= 1)
{
result <<= 1;
if ((value & 1) == 1)
result |= 1;
value >>= 1;
}
return result;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
提示
- 用无符号整数
1的右移来判断unsigned int的二进制位数大小,从而使程序具有可移植性
#
编程练习 4
编写一组函数,实现位数组。函数的原型应该如下
void set_bit( char bit_array[], unsigned bit_number );
void clear_bit( char bit_array[], unsigned bit_number );
void assign_bit( char bit_array[], unsigned bit_number, int value );
int test_bit( char bit_array[], unsigned bit_number );
2
3
4
5
6
7
每个函数的第 1 个参数是个字符数组,用于实际存储所有的位。第 2 个参数用于标识需要访问的位。函数的调用者必须确保这个值不要太大,以至于超出数组的边界。第 1 个函数把指定的位设置为 1 ,第 2 个函数则把指定的位清零。如果 value 的值为 0 ,第 3 个函数把指定的位清 0 ,否则设置为 1 。至于最后一个函数,如果参数中指定的位不是 0 ,函数就返回真,否则返回假
答案
- 代码
/*
** Implements an array of bits in a character array.
*/
#include <limits.h>
#include "bitarray.h"
/*
** Compute the character that will contain the desired bit
*/
unsigned character_offset(unsigned bit_number)
{
return bit_number / CHAR_BIT;
}
/*
** Compute the bit number within the desired character
** Starts at 0
*/
unsigned bit_offset(unsigned bit_number)
{
return bit_number % CHAR_BIT;
}
/*
** Sets the specified bit to one
*/
void set_bit(char bit_array[], unsigned bit_number)
{
bit_array[character_offset(bit_number)] |= 1 << bit_offset(bit_number);
}
/*
** Clear the specified bit to zero
*/
void clear_bit(char bit_array[], unsigned bit_number)
{
bit_array[character_offset(bit_number)] &= ~(1 << bit_offset(bit_number));
}
/*
** Set the specified bit to zero if the "value" is zero,
** otherwise it sets the bit to one
*/
void assign_bit(char bit_array[], unsigned bit_number, int value)
{
if (value == 0)
clear_bit(bit_array, bit_number);
else
set_bit(bit_array, bit_number);
}
/*
** Return true if the specified bit is nonzero, else false.
*/
int test_bit(char bit_array[], unsigned bit_number)
{
return (bit_array[character_offset(bit_number)] & 1 << bit_offset(bit_number)) != 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
bitarray.h的代码如下void set_bit(char bit_array[], unsigned bit_number); void clear_bit(char bit_array[], unsigned bit_number); void assign_bit(char bit_array[], unsigned bit_number, int value); int test_bit(char bit_array[], unsigned bit_number);1
2
3
4
5
6
7
注意
- 注意
bit_array中存储的并不是字符'0','1',而是实际的二进制位- 因此
bit_number需要转换为bit_array中实际的下标
- 因此
test_bit明确要求返回true和false,则尽量让其值返回为0和1
#
编程练习 5
编写一个函数,把一个给定的值存储到一个整数中指定的几个位。它的原型如下:
int store_bit_field(int original_value,
int value_to_store,
unsigned starting_bit, unsigned ending_bit);
2
3
假定整数中的位是从右向左进行编号。因此,起始位的位置不会小于结束位的位置。 为了更清楚地说明,函数应该返回下列值:
| 原始值 | 需要储存的值 | 起始值 | 结束位 | 返回值 |
|---|---|---|---|---|
0x0 | 0x1 | 4 | 4 | 0x10 |
0xffff | 0x123 | 15 | 4 | 0x123f |
0xffff | 0x123 | 13 | 9 | 0xc7ff |
提示:把一个值存储到一个整数中指定的几个位分为5个步骤。以上表最后一行为例:
创建一个掩码(
mask),它是一个值,其中需要存储的位置相对应的那几个位设置为1。此时掩码为0011 1110 0000 0000用掩码的反码对原值执行
AND操作,将那几个位设置为0。原值1111 1111 1111 1111,操作后变为1100 0001 1111 1111将新值左移,使它与那几个需要存储的位对齐。新值
0000 0001 0010 0011(0x123),左移后变为0100 0110 0000 0000把移位后的值与掩码进行位
AND操作,确保除那几个需要存储的位之外的其余位都设置为0。进行这个操作之后,值变为0000 0110 0000 0000把结果值与原值进行位
OR操作,结果为1100 0111 1111 1111(0xc7ff),也就是最终的返回值
在所有任务中,最困难的是创建掩码。你一开始可以把 ~0 这个值强制转换为无符号值,然后再对它进行移位
答案
- 代码
#include <limits.h>
#define INT_BITS (CHAR_BIT * sizeof(int))
/*
** Store a value in an arbitrary field in an integer.
*/
int store_bit_field(int original_value,
int value_to_store,
unsigned starting_bit, unsigned ending_bit)
{
unsigned mask;
/*
** Step 1: creat mask
*/
mask = (unsigned)-1;
mask >>= INT_BITS - (starting_bit - ending_bit + 1);
mask <<= ending_bit;
/*
** Validate the bit parameters, if an error is found, do nothing.
*/
if (starting_bit < INT_BITS && ending_bit < INT_BITS &&
starting_bit >= ending_bit)
{
/*
** Step 2: using the one's complement of the mask,
** clear all the bits in the field of original_value
*/
original_value &= ~mask;
/*
** Step 3: shift the new value left so that
** it is aligned in the filed on the right
*/
value_to_store <<= ending_bit;
/*
** Step 4: and the shifted value with the mask to
** ensure that it has no bits outside of the filed
*/
value_to_store &= mask;
/*
** Step 5: or the resulting value into the original integer
*/
original_value |= value_to_store;
}
return original_value;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
提示
- 具体的操作过程以题目中给出的示例进行理解,不要先入为主
- 标准说明无符号数所有的移位操作均为逻辑移位
#define INT_BITS (CHAR_BIT * sizeof(int))- 此语句可得
int类型的二进制位数
- 此语句可得
starting_bit和ending_bit的含义不要弄反了,同时要对其值进行校验