
 第 8 章 数组
第 8 章 数组
# 第 8 章 数组
# 一维数组
书本内容

# 数组名
书本内容

# 下标引用
书本内容

# 指针与下标
书本内容

# 指针的效率
书本内容

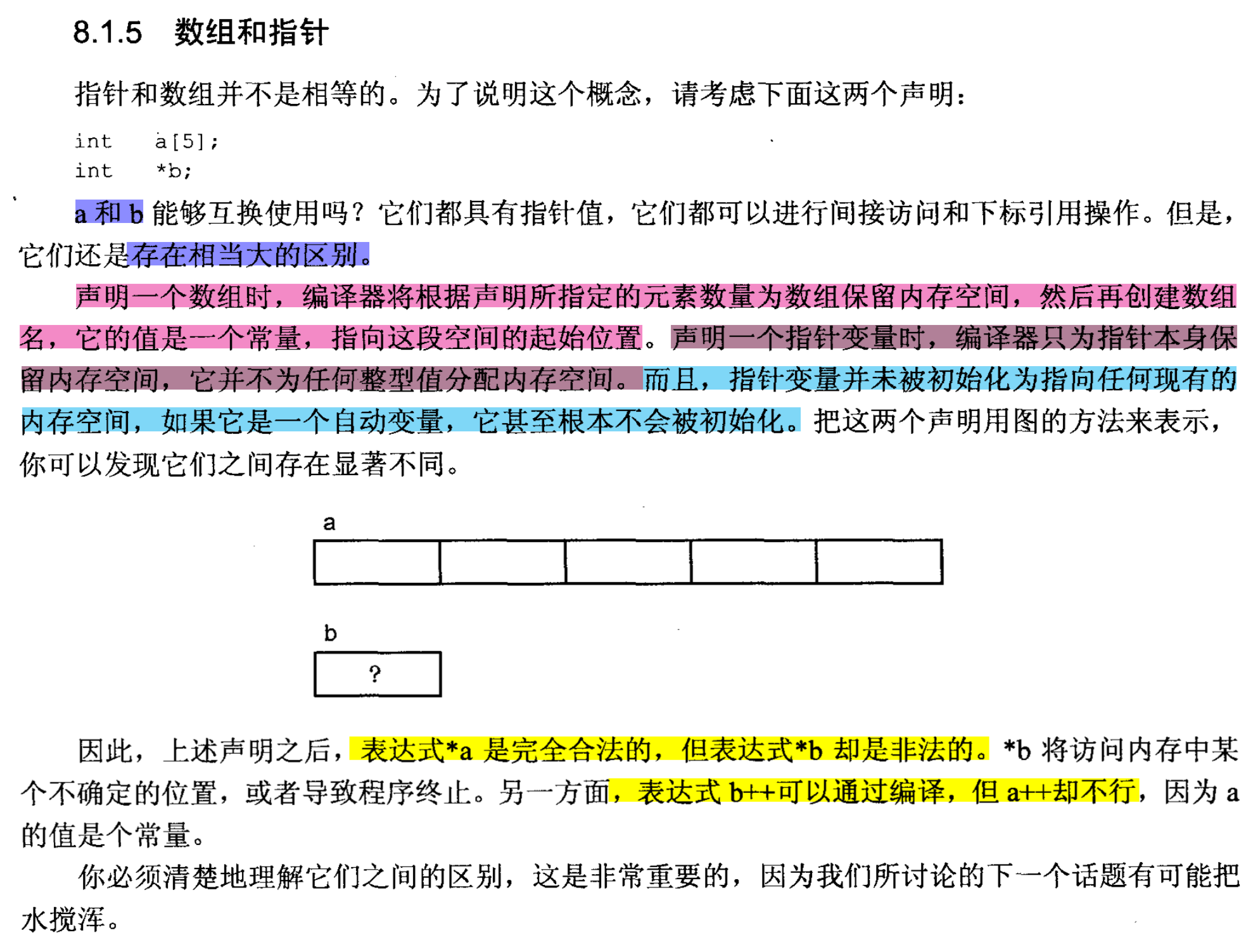
# 数组和指针
书本内容
# 作为函数参数的数组名
书本内容

# 声明数组参数
书本内容

注意
- 仅仅作为函数形参时,
char *string和char string[]才是相等的 - 在其它上下文环境中,此两者并不相等
# 初始化
书本内容

# 不完整的初始化
书本内容

# 自动计算数组长度
书本内容

# 字符数组的初始化
书本内容

# 多维数组
书本内容

# 存储顺序
书本内容

# 数组名
书本内容

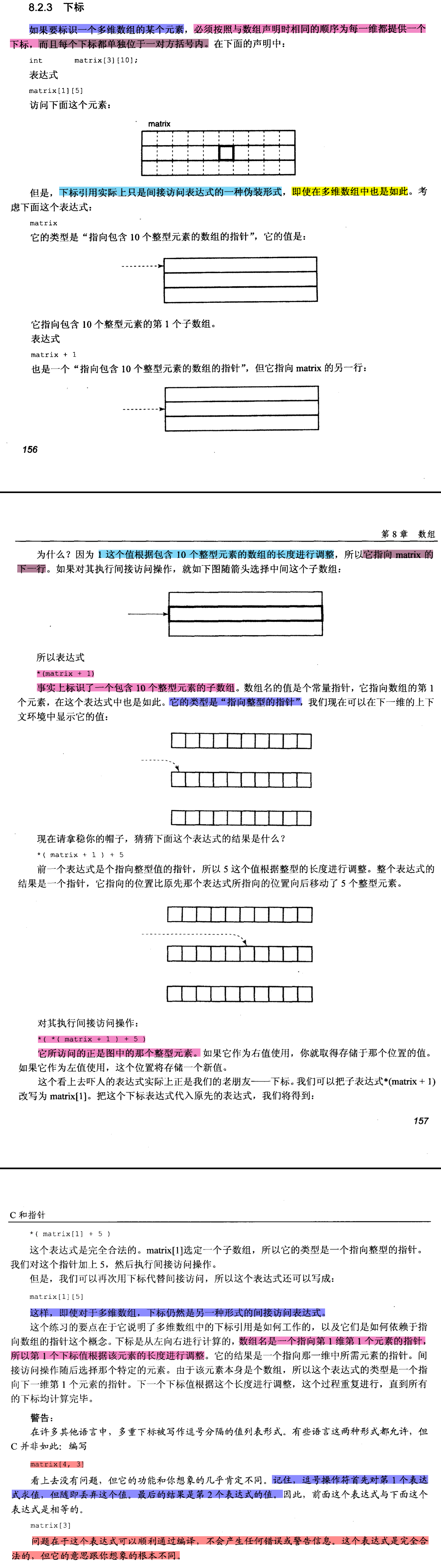
# 下标
书本内容
# 指向数组的指针
书本内容

# 作为函数参数的多维数组
书本内容

# 初始化
书本内容

# 数组长度自动计算
书本内容

# 指针数组
书本内容

# 总结
书本内容

# 问题
#
问题 1
1.根据下面给出的声明和数据,对每个表达式进行求值并写出它的值。在对每个表达式进行求值时使用原先给出的值(也就是说,某个表达式的结果不影响后面的表达式)。假定 ints 数组在内存中的起始位置是100,整型值和指针的长度都是4个字节。
int ints[20] = {
10, 20, 30, 40, 50, 60, 70, 80, 90, 100,
110, 120, 130, 140, 150, 160, 170, 180, 190, 200
};
/* ( Other declarations ) */
int *ip = ints + 3;
2
3
4
5
6
答案
| 表达式 | 值 | 表达式 | 值 |
|---|---|---|---|
ints | 100 | ip | 112 |
ints[4] | 50 | ip[4] | 80 |
ints + 4 | 116 | ip + 4 | 128 |
*ints + 4 | 14 | *ip + 4 | 44 |
*(ints + 4) | 50 | *(ip + 4) | 80 |
ints[-2] | 非法 | ip[-2] | 20 |
&ints | 100 | &ip | 未知 |
&ints[4] | 116 | &ip[4] | 128 |
&ints + 4 | 116 | &ip + 4 | 未知 |
&ints[-2] | 非法 | &ip[-2] | 104 |
#
问题 2
表达式 array[i+j] 和 i+j[array] 是不是相等?
答案
- 不相等,第 2 个表达式等价于
array[j] + i
#
问题 3
3.下面的声明试图按照从1开始的下标访问数组 data,它能行吗?
int actual_data[ 20 ];
int *data = actual_data - 1;
2
答案
- 可行,但是如果程序试图使用
*data,则会导致不可预料的结果
#
问题 4
- 下面的循环用于测试某个字符串是否是回文,请对它进行重写,用指针变量代替下标。
char buffer[SIZE];
int front, rear;
front = 0;
rear = strlen( buffer ) - 1;
while( front < rear ){
if( buffer[front] != buffer[rear] )
break;
front += 1;
rear -= 1;
}
if( front >= rear ){
printf( "It is a palindrome!\n" );
}
2
3
4
5
6
7
8
9
10
11
12
13
14
答案
代码
char buffer[SIZE]; char *front, *rear; front = buffer; rear = buffer + strlen(buffer) - 1; while (front < rear) { if (*front != *rear) break; front++; rear--; } if (front >= rear) { printf("It is a palindrome!\n"); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#
问题 5
指针在效率上可能强于下标,这是使用它们的动机之一。那么什么时候使用下标是合理的,尽管它在效率上可能有所损失?
答案
- 一般情况下,使用下标均是合理的
- 因为一般情况下,一个程序 80% 的运行时间用于执行 20% 的代码,所以其他 80% 的代码对效率不是很敏感
- 因此使用指针获得的效率上的提升,可能抵不上其他方面(如可维护性)的损失
#
问题 6
在你的机器上编译函数try1至try5,并分析结果的汇编代码。你的结论是什么?
⌛tag+todo CSAPP 学完后再来做
答案
#
问题 7
测试你对前一个问题的结论,方法是运行每一个函数并对它们的执行时间进行计时。把数组的元素增加到几千个,增加试验的准确性,因为此时复制所占用的时间远远超过程序不相关部分所占用的时间。同样,在一个循环内部调用函数,让它重复执行足够多的次数,这样你可以精确地为执行时间计时。为这个试验两次编译程序——一次不使用任何优化措施,另一次使用优化措施。如果你的编译器可以提供选择,请选择优化措施以获得最佳速度。
⌛tag+todo 查 C 如何对运行时间计时
答案
#
问题 8
下面的声明取自某个源文件:
int a[10];
int *b = a;
2
但在另一个不同的源文件中,却发现了这样的代码:
extern int *a;
extern int b[];
int x, y;
...
x = a[3];
y = b[3];
2
3
4
5
6
请解释一下,当两条赋值语句执行时会发生什么?(假定整型和指针的长度都是4个字节。)
答案
- 第一条赋值语句,编译器认为
a是一个整型指针变量,因此a[3]会首先取出其中储存在a中的值,然后再加上12- 但是
a实际上存放的是一个整型数组,将a当做一个整型指针变量,取其中存储的值,实际上是取数组的前 4 个字节(与整型指针的长度相同,对于整型数组,其提取的是数组的第 1 个元素)。然后再加上 12 后,结果被解释为地址,再对其进行间接访问 - 作为结果,其要么返回对应地址的值(此值往往是不可预测的); 要么由于地址错误而导致程序失败(大多数会是这种情况)
- 但是
- 第二条赋值语句,编译器认为
b是一个数组名,所以 12 会加到b的存储地址,然后间接访问操作会从那里提取值。但事实上,b是一个指针,其储存的地址是不可预计的,将其地址向后偏移 12 再读取的内容是不可预料的。
注意
指针和数组虽然存在关联,但两者绝不是等同的
#
问题 9
编写一个声明,初始化一个名叫coin_values的整型数组,各个元素的值分别表示当前各种美元硬币的币值。
答案
int coin_values = {1, 5, 10, 25, 50, 100};
#
问题 10
给定下列声明
int array[4][2];
请写出下面每个表达式的值。假定数组的起始位置为1000,整型值在内存中占据2个字节的空间。
| 表达式 | 值 |
|---|---|
array | |
array+2 | |
array[3] | |
array[2] - 1 | |
&array[1][2] | |
&array[2][0] |
答案
| 表达式 | 值 |
|---|---|
array | 1000 |
array+2 | 1008 |
array[3] | 1012 |
array[2] - 1 | 1006 |
&array[1][2] | 1008 |
&array[2][0] | 1008 |
#
问题 11
给定下列声明
int array[4][2][3][6];
| 表达式 | 值 | X 的类型 |
|---|---|---|
array | ||
array + 2 | ||
array[3] | ||
array[2] - 1 | ||
array[2][1] | ||
array[1][0] + 1 | ||
array[1][0][2] | ||
array[0][1][0] + 2 | ||
array[3][1][2][5] | ||
&array[3][1][2][5] |
计算上表中各个表达式的值。同时,写出变量x所需的声明,这样表达式不用进行强制类型转换就可以赋值给x。假定数组的起始位置为1000,整型值在内存中占据4个字节的空间。
答案
| 表达式 | 值 | X 的类型 |
|---|---|---|
array | 1000 | int (*x)[2][3][6] |
array + 2 | 1288 | int (*x)[2][3][6] |
array[3] | 1432 | int (*x)[3][6] |
array[2] - 1 | 1216 | int (*x)[3][6] |
array[2][1] | 1360 | int (*x)[6] |
array[1][0] + 1 | 1168 | int (*x)[6] |
array[1][0][2] | 1192 | int *x |
array[0][1][0] + 2 | 1080 | int *x |
array[3][1][2][5] | can not tell | int x |
&array[3][1][2][5] | 1572 | int *x |
#
问题 12
C 的数组按照行主序存储。什么时候需要使用这个信息?
答案
- 当执行任何 "按照元素出现的顺序对元素进行访问" 的操作时。例如
- 初始化一个数组
- 读取或写入超过一个数组元素
- 通过移动指针访问数组底层内存 "压扁" 数组
#
问题 13
给定下列声明
int array[4][5][3];
把下列各个指针表达式转换为下标表达式。
| 表达式 | 下标表达式 |
|---|---|
*array | |
*(array + 2) | |
*(array + 1) + 4 | |
*(*(array + 1) + 4) | |
*(*(*(array + 3) + 1) + 2) | |
*(*(*array + 1) + 2) | |
*(**array + 2) | |
**(*array + 1) | |
***array |
答案
| 表达式 | 下标表达式 |
|---|---|
*array | array[0] |
*(array + 2) | array[2] |
*(array + 1) + 4 | array[1] + 4 |
*(*(array + 1) + 4) | array[1][4] |
*(*(*(array + 3) + 1) + 2) | array[3][1][2] |
*(*(*array + 1) + 2) | array[0][1][2] |
*(**array + 2) | array[0][0][2] |
**(*array + 1) | array[0][1][0] |
***array | array[0][0][0] |
#
问题 14
多维数组的各个下标必须单独出现在一对方括号内。在什么条件下,下列这些代码段可以通过编译而不会产生任何警告或错误信息?
int array[10][20];
...
i = array[3,4];
2
3
答案
- 当
i被声明为指向整型的指针时,上述声明不会产生警告或错误信息
#
问题 15
给定下列声明
unsigned int which;
int array[ SIZE ];
2
下面两条语句哪条更合理?为什么?
if(array[ which ] == 5 && which < SIZE ) ...
if( which < SIZE && array[ which ] == 5 )...
2
答案
- 第 2 条语句更为合理
- 第 2 条语句利用
&&运算符的 "知路求值" 的性质,可以确保which作为下标使用时,不会超过数组的范围
- 第 2 条语句利用
#
问题 16
在下面的代码中,变量 array1 和 array2 有什么区别(如果有的话)?
void function( int array1[10] ){
int array2[10];
...
}
2
3
4
答案
array1实际上是一个整型指针,它指向传入数组的首地址,其值可以在函数内被修改。而且无法保证传入的数组具有 10 个元素array2是数组名,相当于一个常量指针,其值不可被更改。array2指向此函数中为 10 个整型数分配的储存空间的首地址
#
问题 17
解释下面两种 const 关键字用法的显著区别所在
void function( int const a, int const b[] ) {
答案
- 第 1 个参数是一个标量,其获得是原参数的一份拷贝,对拷贝的修改并不会影响原参的数的值,所以此处
const的作用并不是为了防止原参数被修改- 但是在函数内部不能再对参数
a进行修改
- 但是在函数内部不能再对参数
- 第 2 个参数实际是一个指向整型的指针。传递给函数的是指针的拷贝,对其进行修改不会影响原指针,但函数可以通赤对指针进行间接访问操作修改调用程序的值。
const关键字可以避免这种修改
#
问题 18
下面的函数原型可以改写为什么形式,但保持结果不变?
void function( int array[3][2][5] );
答案
- 可改为
void function (int array[][2][5]) - 或
void function (int (*array)[2][5])
#
问题 19
在程序8.2的关键字查找例子中,字符指针数组的末尾增加了一个 NULL 指针,这样我们就不需要知道表的长度。那么,矩阵方案应如何进行修改,使其达到同样的效果呢?写出用于访问修改后的矩阵的 for 语句
答案
- 可以向数组中添加一个空字符串
- 修改后的矩阵的
for语句如下for(kwp = keyword_table; **kwp != '\0'; kwp++)
# 编程练习
#
编程练习 1
编写一个数组的声明,把数组的某些特定位置初始化为特定的值。这个数组的名字应该叫 char_value ,它包含 3 × 6 × 4 × 5 个无符号字符。下面的表中列出的这些位置应该用相应的值进行静态初始化。
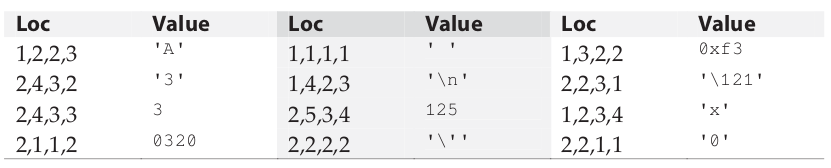
那些在上面的表中未提到的位置应该被初始化为二进制值0(不是字符‘0’)。注意:应该使用静态初始化,在你的解决方案中不应该存在任何可执行代码!
尽管并非解决方案的一部分,你很可能想编写一个程序,通过打印数组的值来验证它的初始化。由于某些值并不是可打印的字符,所以请把这些字符用整型的形式打印出来(用八进制或十六进制输出会更方便一些)。
答案
代码
unsigned char char_value[3][6][4][5] = { /* [0][][][] */ {}, /* [1][][][] */ { /* [1][0][][] */ {}, /* [1][1][][] */ { /* [1][1][0][] */ {}, /* [1][1][1][] */ {0, ' '}, }, /* [1][2][][] */ { /* [1][2][0][] */ {}, /* [1][2][1][] */ {}, /* [1][2][2][] */ {0, 0, 0, 'A'}, /* [1][2][3][] */ {0, 0, 0, 0, 'x'}, }, /* [1][3][][] */ { /* [1][3][0][] */ {}, /* [1][3][1][] */ {}, /* [1][3][2][] */ {0, 0, 0xf3}, }, /* [1][4][][] */ { /* [1][4][0][] */ {}, /* [1][4][1][] */ {}, /* [1][4][2][] */ {0, 0, 0, '\n'}, }, }, /* [2][][][] */ { /* [2][0][][] */ {}, /* [2][1][][] */ { /* [2][1][0][] */ {}, /* [2][1][1][] */ {0, 0, 0320}, }, /* [2][2][][] */ { /* [2][2][0][] */ {}, /* [2][2][1][] */ {0, '0'}, /* [2][2][2][] */ {0, 0, '\''}, /* [2][2][3][] */ {0, '\121'}, }, /* [2][3][][] */ {}, /* [2][4][][] */ { /* [2][4][0][] */ {}, /* [2][4][1][] */ {}, /* [2][4][2][] */ {}, /* [2][4][3][] */ {0, 0, '3', 3}, }, /* [2][5][][] */ { /* [2][5][0][] */ {}, /* [2][5][1][] */ {}, /* [2][5][2][] */ {}, /* [2][5][3][] */ {0, 0, 0, 0, 125}, }, }, };1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
#
编程练习 2
美国联邦政府使用下面这些规则计算1995年每个公民的个人收入所得税
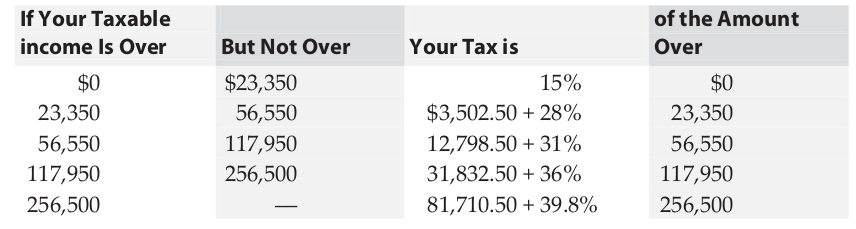
为下面的函数原型编写函数定义:
float single_tax( float income );
参数 income 表示应征税的个人收入,函数的返回值就是 income 应该征收的税额。
答案
代码
#include <float.h> static float limits[] = {0, 23350, 56550, 117950, 256500, FLT_MAX}; static float base_tax[] = {0, 3502.5, 12798.5, 31832.5, 81710.5}; static float percentage[] = {0.15, 0.28, 0.31, 0.36, 0.396}; /* ** Calculate the 1995 U.S appropriate amount of tax. */ float single_tax(float income) { int category; float tax; tax = 0; if (income > 0) { for (category = 1; income >= limits[category]; category++) ; category--; tax = base_tax[category] + percentage[category] * (income - limits[category]); } return tax; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
提示
- 借助数组进行税额分区,方便代码书写
- 借助
float.h中的FLT_MAX来断定收入所在的税额区间
#
编程练习 3
单位矩阵(identity matrix)就是一个正方形矩阵,它除了主对角线的元素值为1以后,其余元素的值均为0。例如:
1 0 0
0 1 0
0 0 1
2
3
就是一个3×3的单位矩阵。编写一个名叫 identity_matrix 的函数,它接受一个10×10整型矩阵为参数,并返回一个布尔值,提示该矩阵是否为单位矩阵。
答案
代码
#define TRUE 1 #define FALSE 0 /* ** Test a square matrix (10 * 10) to see if it is an identity matrix. */ int identity_matrix(int (*matrix)[10]) { int row, column; for (row = 0; row < 10; row++) for (column = 0; column < 10; column++) if (matrix[row][column] != (row == column)) return FALSE; return TRUE; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#
编程练习 4
修改前一个问题中的 identity_matrix 函数,它可以对数组进行扩展,从而能够接受任意大小的矩阵参数。函数的第 1 个参数应该是一个整型指针,你需要第 2 个参数,用于指定矩阵的大小
答案
代码
#define TRUE 1 #define FALSE 0 /* ** Test a square matrix (size * size) to see if it is an identity matrix. */ int identity_matrix(int *matrix, int size) { int row, column; for (row = 0; row < size; row++) for (column = 0; column < size; column++) if (*matrix++ != (row == column)) return FALSE; return TRUE; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
提示
- 调用函数时,应按照下列格式
int matrix[SIZE][SIZE];
identity_matrix((int *)matrix, SIZE);
2
- 如果不加
(int *),编译器会警告类型不匹配,实际加不加没有影响,都是传值调用
#
编程练习 5

答案
代码
/* ** multiply two matrices */ void matrix_multiply(int *m1, int *m2, int *r, int x, int y, int z) { int row, column; register int k, *m1p, *m2p; for (row = 0; row < x; row++) for (column = 0; column < z; column++) { *r = 0; m1p = m1 + row * y; m2p = m2 + column; for (k = 0; k < y; k++) { *r += *m1p * *m2p; m1p++; m2p += z; } r++; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
加速措施
- 最内层循环中需要使用的变量定义为寄存器变量
- 遍历 A, B 两个数组的指针,写为按常数递增的形式,以期减少计算指针地址时的计算量
#
编程练习 6

答案
代码
#include <stdarg.h> int array_offset(int arrayinfo[], ...) { int dimensions; int subscripts[10]; int hi, lo, cur; int offset; va_list var_args; int i; dimensions = arrayinfo[0]; if (dimensions < 1 || dimensions > 10) return -1; va_start(var_args, arrayinfo); for (i = 0; i < dimensions; i++) subscripts[i] = va_arg(var_args, int); va_end(var_args); for (i = 0, offset = 0; i < dimensions; i++) { lo = *++arrayinfo; hi = *++arrayinfo; cur = subscripts[i]; if (cur < lo || cur > hi) return -1; offset *= hi - lo + 1; offset += cur - lo; } return offset; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#
编程练习 7

答案
代码
#include <stdarg.h> int array_offset(int arrayinfo[], ...) { int dimensions; int subscripts[10]; int hi, lo, cur; int offset; va_list var_args; int i; dimensions = arrayinfo[0]; if (dimensions < 1 || dimensions > 10) return -1; va_start(var_args, arrayinfo); for (i = 0; i < dimensions; i++) subscripts[i] = va_arg(var_args, int); va_end(var_args); arrayinfo += dimensions * 2; for (i = dimensions - 1, offset = 0; i >= 0; i--) { hi = *arrayinfo--; lo = *arrayinfo--; cur = subscripts[i]; if (cur < lo || cur > hi) return -1; offset *= hi - lo + 1; offset += cur - lo; } return offset; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#
编程练习 8

答案
代码
#include <stdio.h> #include <stdlib.h> #define SIZE 1 #define TRUE 1 #define FALSE 0 static int board[SIZE][SIZE]; void print_board(int n_solutions) { int row, column; printf("Solution#%d\n", n_solutions); for (row = 0; row < SIZE; row++, putchar('\n')) for (column = 0; column < SIZE; column++, putchar(' ')) if (board[row][column]) putchar('Q'); else putchar('0'); putchar('\n'); } int conflict(int row, int column) { int i; for (i = 0; i < row; i++) { if (board[i][column]) return TRUE; if (i - row + column >= 0 && board[i][i - row + column]) return TRUE; if (row - i + column < SIZE && board[i][row - i + column]) return TRUE; } return FALSE; } void place_queue(int row) { static int n_solutions; int column; if (row < SIZE) for (column = 0; column < SIZE; column++) if (!conflict(row, column)) { board[row][column] = TRUE; place_queue(row + 1); board[row][column] = FALSE; } if (row == SIZE) print_board(++n_solutions); } int main(void) { place_queue(0); return EXIT_SUCCESS; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61