
 第 4 章 处理器体系结构
第 4 章 处理器体系结构
# 第 4 章 处理器体系结构
指令集体系结构(Instruction-Set Architecture, ISA)
- 一个处理器支持的指令和指令的字节级编码称为它的指令集体系结构
- ISA 在编译器编写者和处理器设计人员之间提供了一个概念抽象层
流水线化的处理器 (pipelined processor)
- ISA 模型在抽象上是按顺序指令执行的
- 通过将每条指令的执行分解为多个步骤,每个步骤由一个独立的硬件部分或阶段来处理
- 指令的执行需要经过流水线的各个阶段
- 每个时钟周期都有一条新的指令进行流水线
- 如此,处理器可以同时执行多条指令的不同阶段
- 借助流水线,处理器能获得更高的性能
# 4.1 Y86-64 指令集体系结构
# 4.1.1 程序员可见的状态
笔记
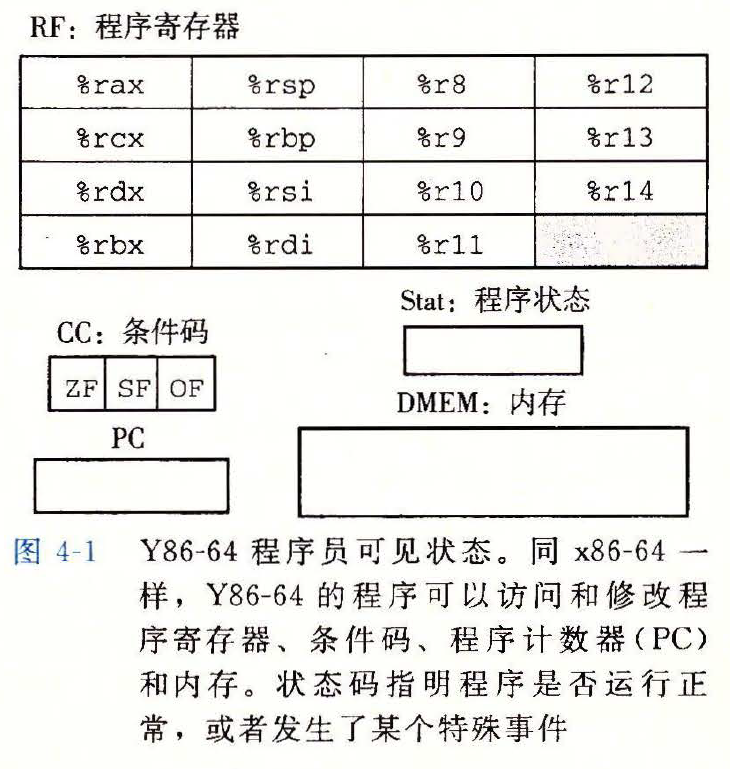
- 程序员可见状态包括
- RF: 程序寄存器
- CC: 条件码
- PC: 程序计数器
- Stat: 程序状态
- DMEM: 内存
程序员可见状态图示
# 4.1.2 Y86-64 指令
笔记
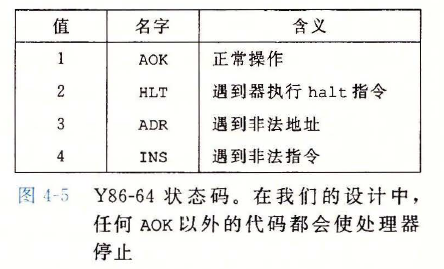
halt指令停止指令的执行,并将状态码设置为HLTY86-64 指令集

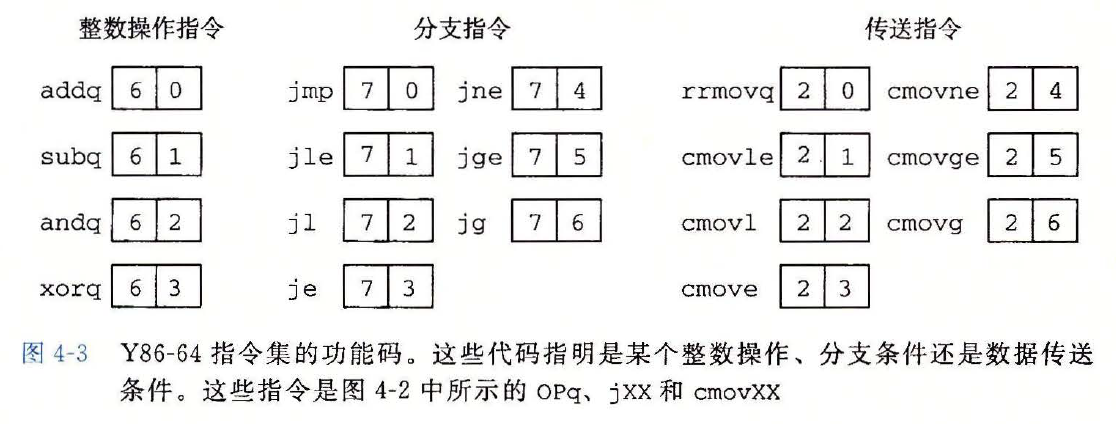
# 4.1.3 指令编码
笔记
Y86-64 指令集的功能码
#
Y86-64 程序寄存器的标识符
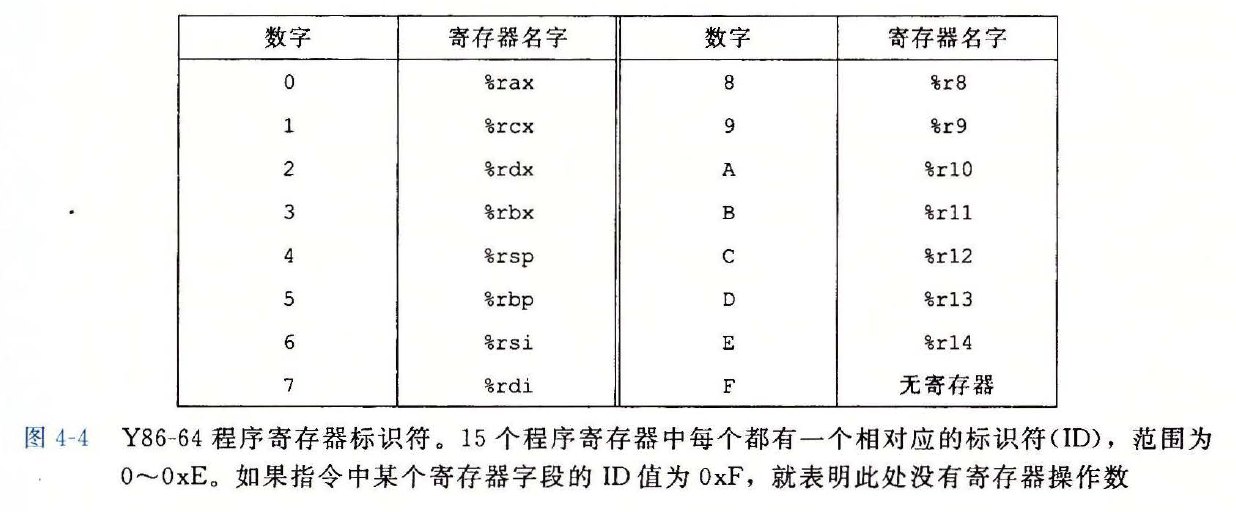
- 只需要一个寄存器操作数的指令将另一个寄存器指示符设置为
0XF
- 分支指令和调用指令的目的是一个绝对地址
- 所有的整数采用小端法编码
指令集的一个重要特性是字节编码必须要有唯一的解释
- 这个性质保证了处理器可以无二义性的执行目标代码程序
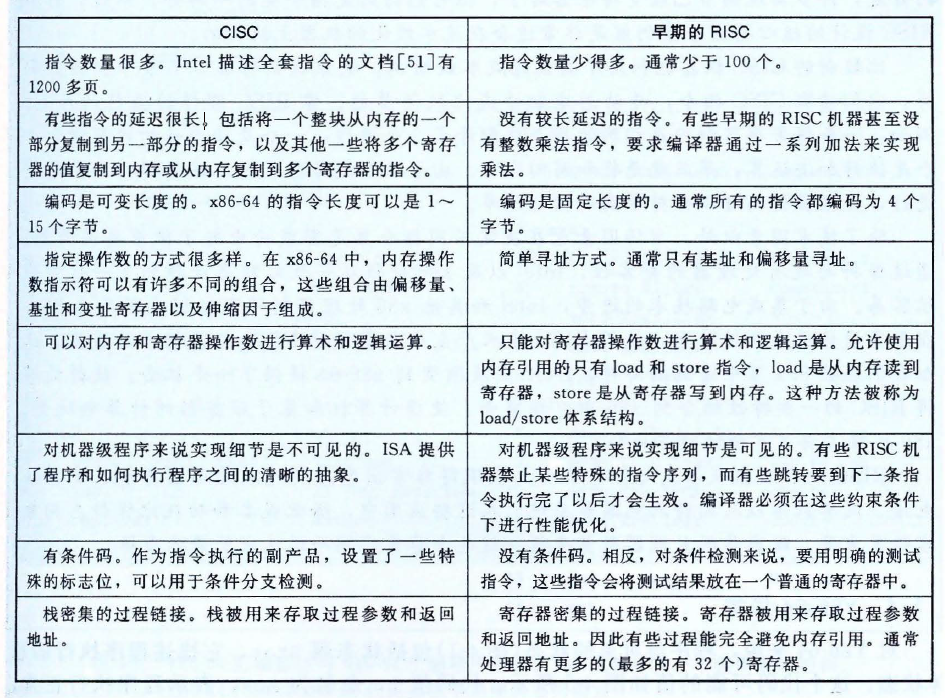
CISC 和 RISC
- CISC,复杂指令集计算机
- RISC,精简指令集计算机
CISC 和 RISC 的对比
# 4.1.4 Y86-64 异常
Y86-64 状态码
# 4.1.5 Y86-64 程序
笔记
- 以
.开头的词是 汇编器伪指令(assembler directives)- 它们会告诉汇编器调整地址,以便在那儿产生代码或插入一些数据
# 4.1.6 一些 Y86-64 指令的详情
提示
push %rsp压入的是%rsp中原始的值pop %rsp弹出的是最后一次压入栈中的值
# 4.2 逻辑设计和硬件控制语言 HCL
# 4.2.1 逻辑门
笔记
逻辑门类型
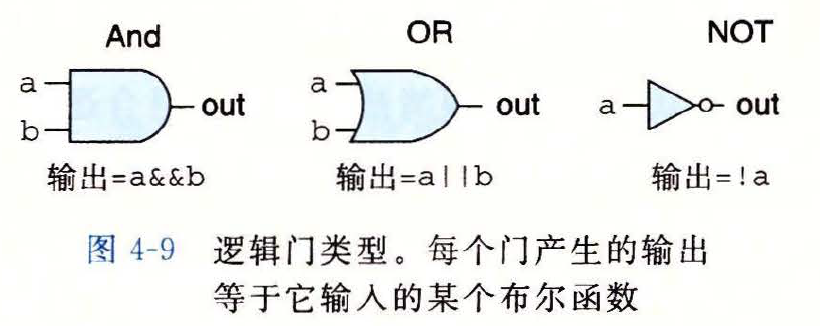
- 逻辑门总是活动的
- 一旦输入变化,则在很短的时间内,输出就会相应地变化
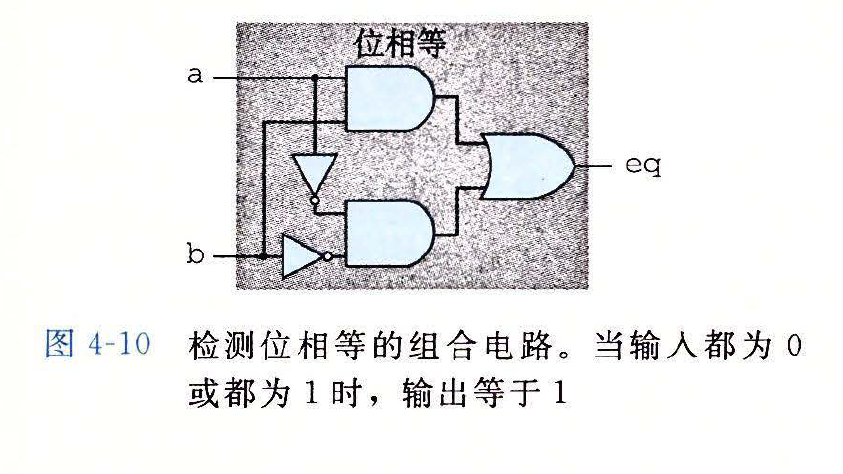
# 4.2.2 组合电路和 HCL 布尔表达式
检测位相等
- HCL 表示
bool eq = (a && b) || (!a && !b)
电路图
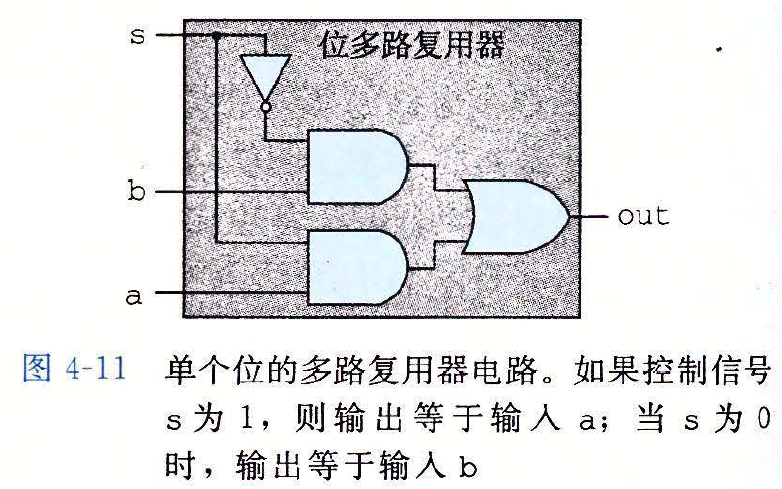
单个位的多路复用器
- HCL 表达式
bool out = (s && a) || (!s && b)
电路图
# 4.2.3 字级组合电路和 HCL 整数表达式
字级相等测试
- HCL 表达式
bool Eq = (A == B)
字级相等测试电路
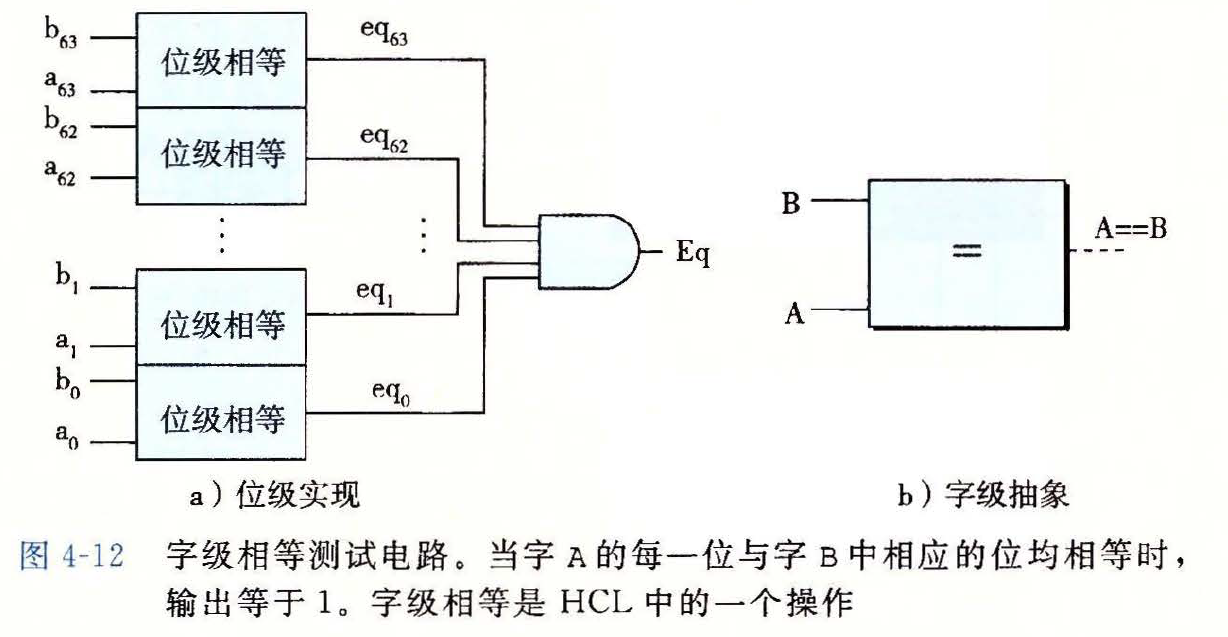
字级的多路利用器
HCL 表达式
word Out = [ s: A; 1: B; ];1
2
3
4- 选择表达式顺序求值,第一个求值为
1的情况会被选中
- 选择表达式顺序求值,第一个求值为
字级多路复用电路图
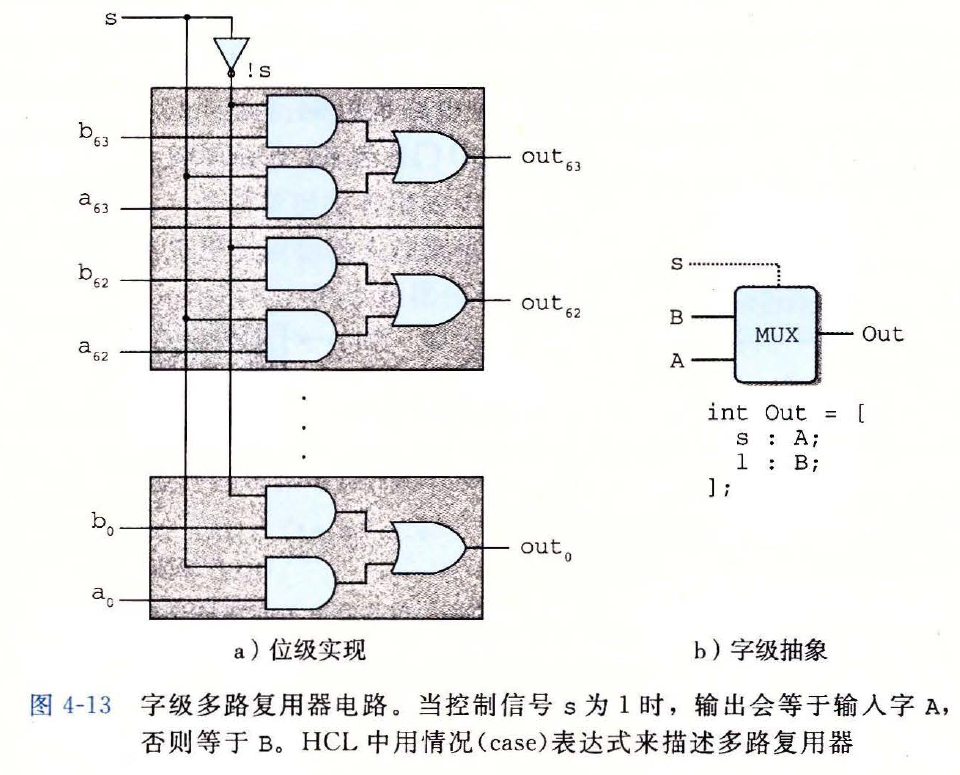
四路复用器
HCL 表达式
word Out4 = [ !s1 && !s0 : A; # 00 !s1 : B; # 01 !s0 : C; # 10 1 : D; # 11 ];1
2
3
4
5
6电路图
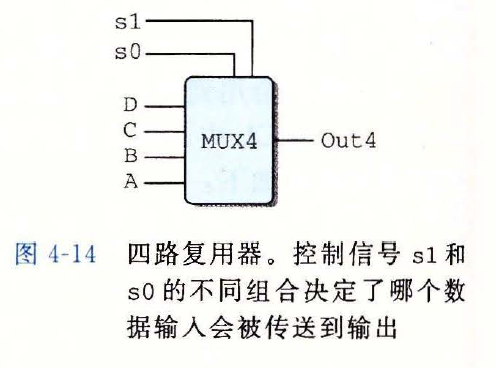
计算 A, B, C 中的最小值
HCL 表达式
word Min3 = [ A <= B && A <= C : A; B <= C : B; 1 :C; ];1
2
3
4
5电路图
算术逻辑单元(ALU)
- 三个输入
- 两个数据输入
- 一个控制输入
根据控制输入的设置,电路会对数据输入执行不同的算术或逻辑操作
ALU 电路示意图
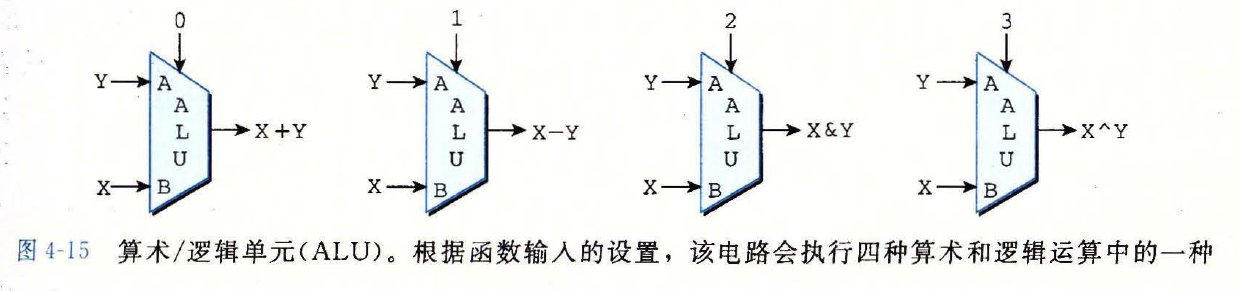
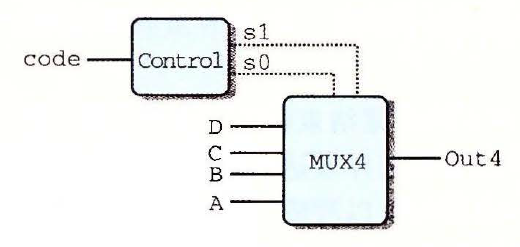
# 4.2.4 集合关系
用两位信号 code 控制四路复用器
HCL 表达式
bool s1 = code in {2, 3}; bool s0 = code in {1, 3};1
2电路示意图
# 4.2.5 存储器和时钟
组合电路从本质上来讲,不储存任何信息
时钟寄存器
- 简称寄存器
- 时钟信号控制寄存器加载输入值
- 只有在时钟的上升沿,才会更新寄存器的值
寄存器操作图示
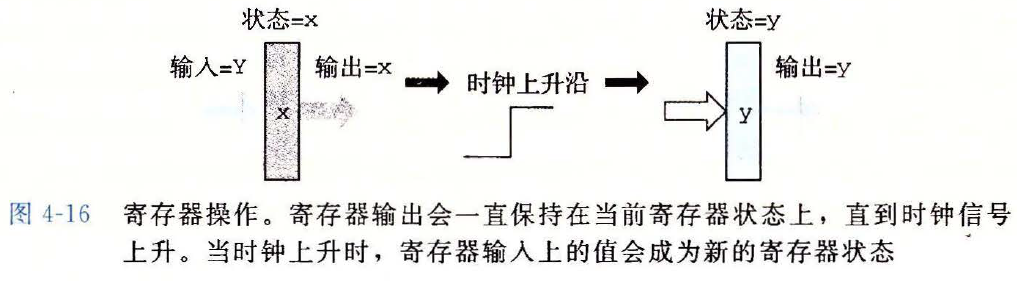
- 在机器级编程中,寄存器代表的是 CPU 中为数不多的可寻址字
- 地址即为寄存器 ID
- 寄存器可以看做电路不同部分中组合逻辑之间的屏障
寄存器文件
寄存器文件示意图
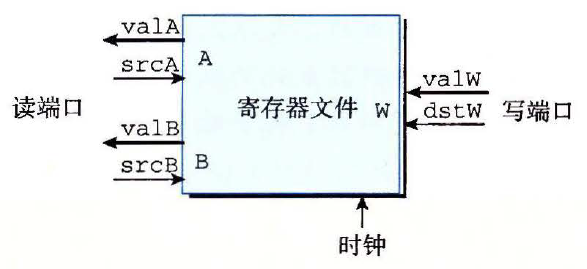
- 从寄存器文件读数据时,可以将其看做一个以地址为输入、数据为输出的组合逻辑块
- 向寄存器文件写入字是由时钟信号控制的
随机访问存储器
- 简称内存
- 用地址选择该读或者该写哪个字
随机访问存储器图示
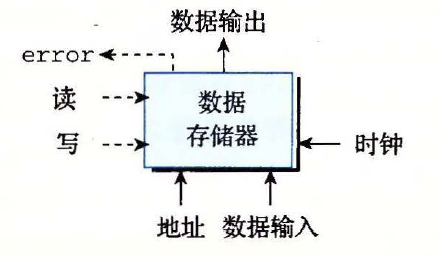
- 从内存中读的操作方式类似于组合逻辑
- 写内存是由时钟控制的
只读存储器用来读指令
# 4.3 Y86-64 的顺序实现
各个变量的含义
| 变量名 | 含义 |
|---|---|
srcA, srcB | 寄存器读端口的地址输入 |
dstW | 寄存器写端口的地址输入 |
valA | 从寄存器 A 读出的数据, 常用于访存阶段 |
valB | 从寄存器 B 读出的数据, 常用于执行阶段 |
valC | 指令中的四字节常数 |
valE | ALU 计算输出的值 |
valM | 从内存中读出的数据 |
valP | 下一条指令的地址 |
valW | 数据输入,一般用于更新寄存器的值 |
SEQ 处理器
- SEQ(sequential)
- 每个时钟周期上, SEQ 执行处理一条完整指令所需的所有步骤
# 4.3.1 将处理组织成阶段
笔记
- 处理一条指令包含很多操作,可以将它们组织成某个特殊的阶段序列
- 每一步的具体处理取决于正在执行的指令
- 创建这样一个框架,有助于设计一个充分利用硬件的处理器
各个阶段
- 取指(fetch)
- 从内存中读取指令字节
- 可能从指令中取出一个四字常数字
ValC - 按顺序执行的方式计算出当前指令的下一条指令的地址
valP
- 译码(decode)
- 从寄存器中读入最多两个操作数,得到值
valA和/或valB - 一般读入指令
rA, rB字段指明的寄存器 - 有些指令(
popq,pushq) 是读寄存器%rsp的
- 从寄存器中读入最多两个操作数,得到值
- 执行(execute)
- ALU 根据指令的内容进行相应的计算,得到的结果记为
valE - 此阶段也可以设置条件码
- 对于条件传送指令,这个阶段会验证条件码和传送条件,如果条件成立,则更新目标寄存器
- 对于跳转指令,这个阶段会决定是不是应该选择分支
- ALU 根据指令的内容进行相应的计算,得到的结果记为
- 访存(memory)
- 将数据写入内存或从内存读出数据,读出的值为
valM
- 将数据写入内存或从内存读出数据,读出的值为
- 写回(write back)
- 写回阶段最多可以写两个结果到寄存器文件
- 更新 PC(PC update)
- 将 PC 设置为下一条指令的地址
笔记
- 设计硬件时,一个非常简单而一致的结构是非常重要的
- 降低复杂度的一种方法是让不同的指令共享尽量多的硬件
- 在硬件上复制逻辑块的成本要比软件中有重复代码的成本大得多
Y86-64 中指令 OPq, rrmovq, irmovq 在顺序实现中的计算
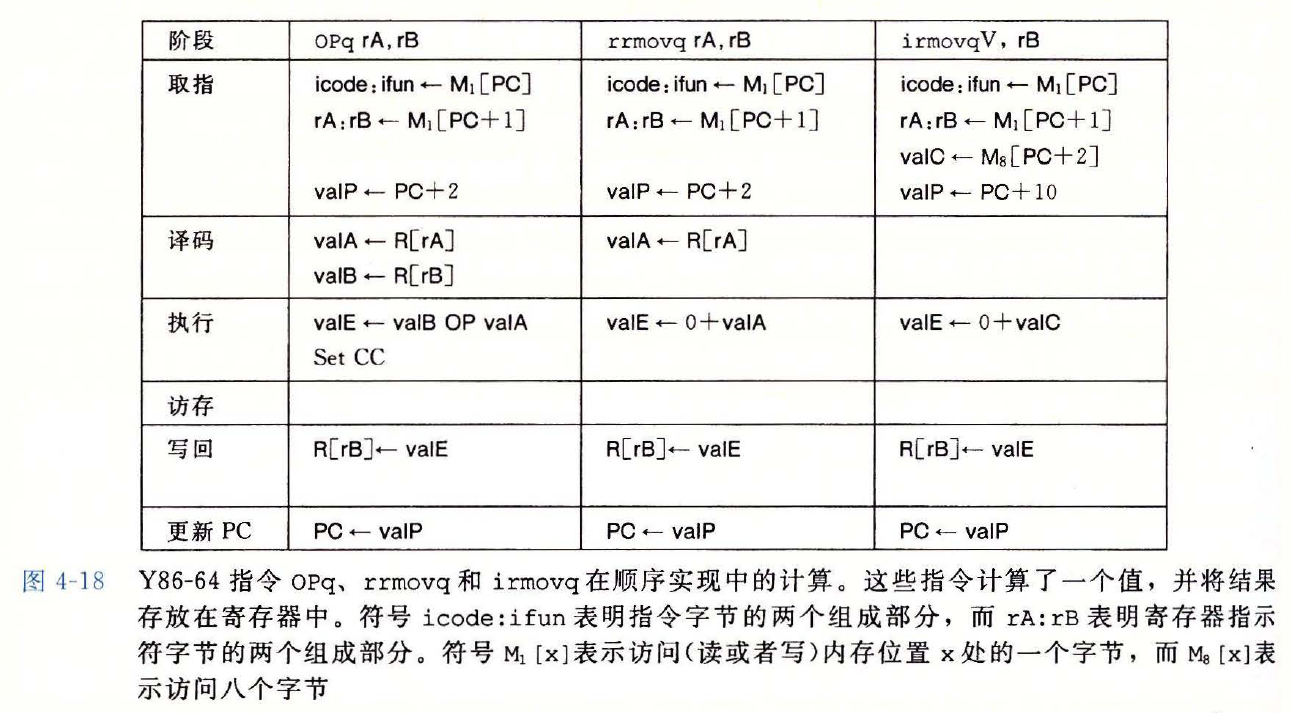
没有明确指定 Set CC,则执行阶段不会设置条件码
Y86-64 中指令 rmmovq, mrmovq 在顺序实现中的计算

Y86-64 中指令 pushq, popq 在顺序实现中的计算

- 注意整体的操作顺序顺序与
popq %rsp和pushq %rsp的行为一致
Y86-64 中指令 jxx, call 和 ret 在顺序实现中的计算
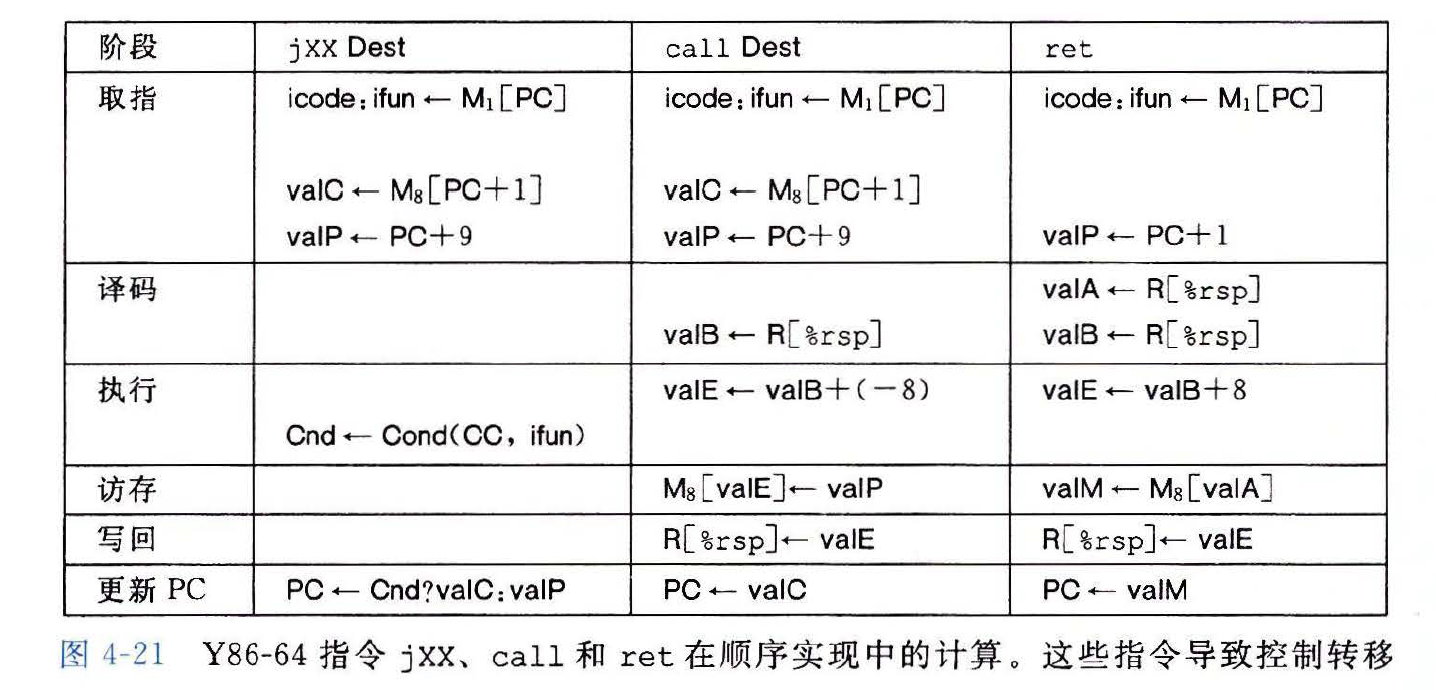
jxx的跳转阶段,通过检查条件码和跳转条件来确定是否要选择分支- 会产生一个一位信号
Cnd
- 会产生一个一位信号
call指令从指令中读出跳转地址,并将下一条指令的地址压入栈中
# 4.3.2 SEQ 的硬件结构
SEQ 的抽象视图
SEQ 抽象视图图示
- 信息沿着线流动,先向上,再向右
- 同各个阶段相关的硬件单元负责执行这些处理
- 在右边,反馈线路向下,包括要写到寄存器文件中的更新值,以及更新的程序计数器值
.jpg)
SEQ 的硬件结构
SEQ 硬件结构图示
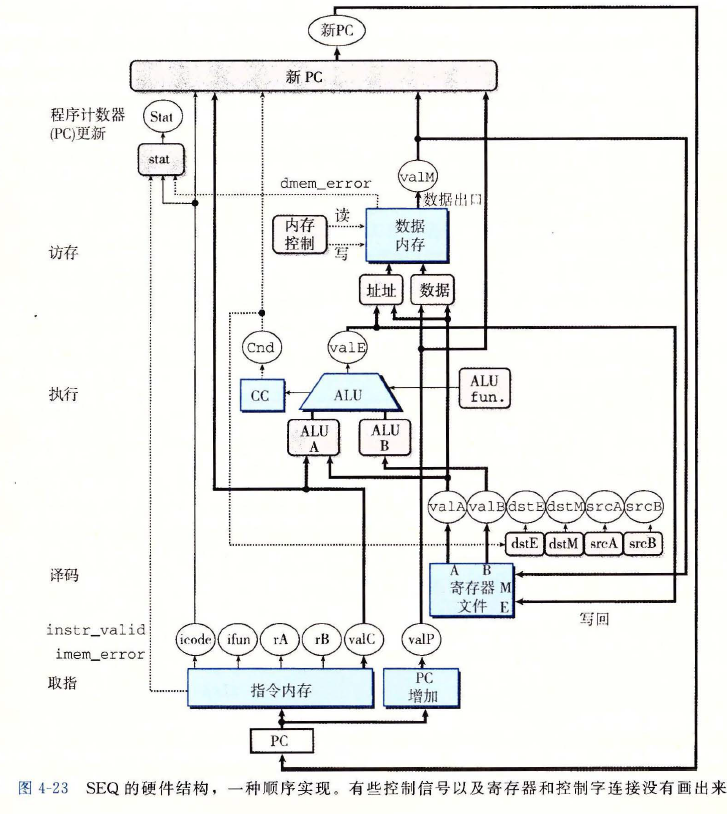
- PC 是 SEQ 中唯一的时钟寄存器
# 4.3.3 SEQ 的时序
各个硬件单元的时序
- 程序计数器
- 每个时钟周期,程序计数器都会装载新的指令地址
- 条件码寄存器
- 只有在执行整数运算指令时,才会装载条件码寄存器
- 数据内存
- 只有在执行
rmmovq、pushq或call指令时,才会写数据内存
- 只有在执行
- 寄存器文件的两个写端口允许每个时钟周期更新两个程序寄存器
- 读操作与组合逻辑类似
- 写操作由时钟控制
遵循 "从不回读" 的原则组织计算
- 处理器从来不需要为了完成一条指令的执行而去读由该指令更新了的状态
- 实例
pushq指令的实现- 用信号
valE既作为寄存器写的数据,也作为内存写的地址 - 不是先将
%rsp减 8,然后再将更新后的%rsp的值作为写操作的地址
- 用信号
- 没有指令必须即设置又读取条件码
用时钟来控制状态单元的更新,以及值通过组合逻辑来传播,足够控制 SEQ 实现中每条指令的计算
- 每次时钟由低变高时,处理器开始执行一条新的指令
SEQ 执行的两个周期图示
.jpg)
# 4.3.4 SEQ 阶段的实现
HCL 描述中使用的常数值
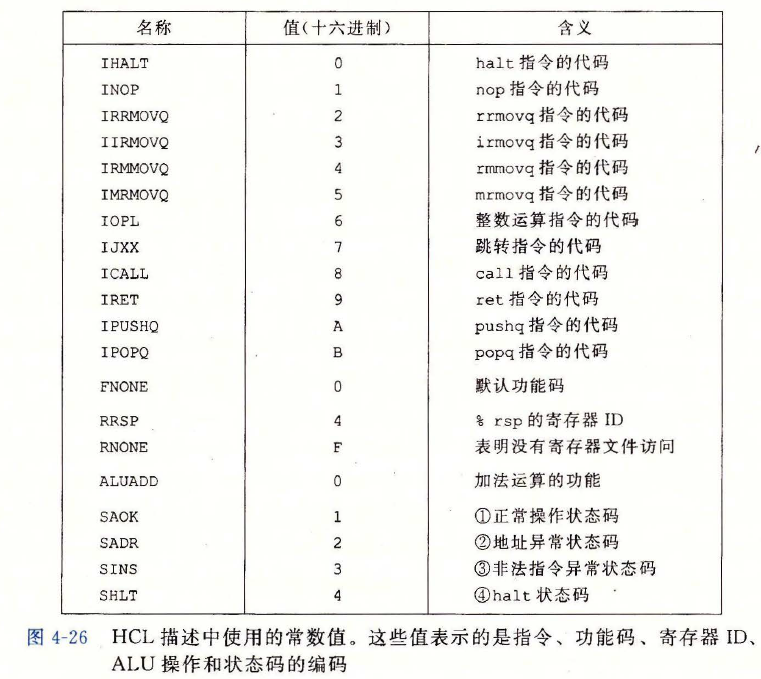
nop指令只是简单的经过各个阶段,除了要将 PC 加 1,不进行任何处理
取指阶段
示意图
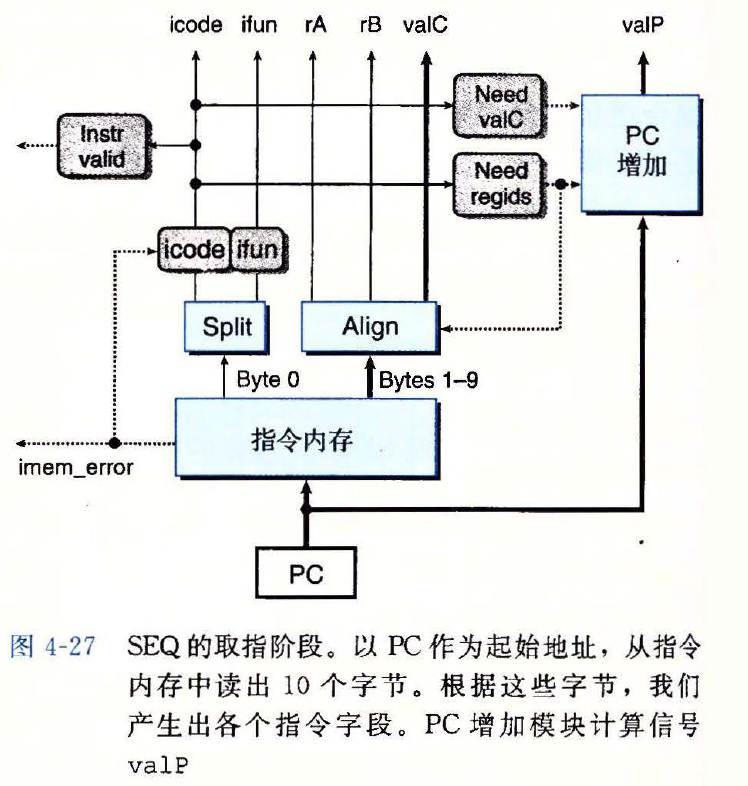
need_regids的 HCL 描述bool need_regids = icode in { IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IOPQ, IPUSHQ, IPOPQ }1
2
3need_valC的 HCL 描述bool need_valC = icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL}1
2
译码和写回阶段
图示
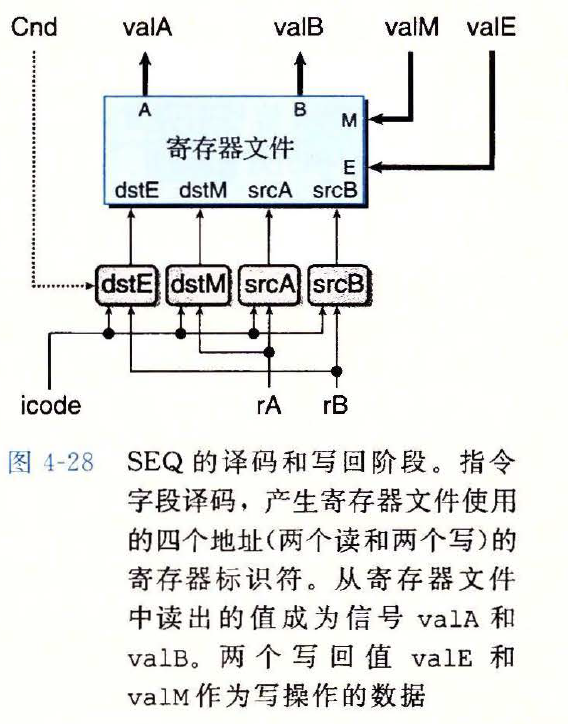
译码阶段
srcA的 HCL 描述word srcA = [ icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ }: rA; icode in { IPOPQ, IRET }: RRSP; 1 : RNONE; # Don't need register ]1
2
3
4
5译码阶段
srcB的 HCL 描述word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ}: rB; icode in { IPUSH, IPOPQ, ICALL, IRET }: RRSP; 1 : RNONE; # Don't need register ]1
2
3
4
5写回阶段
dstE的 HCL 描述- 暂不包括条件移动指令
word dstE = [ icode in { IRRMOVQ, IIRMOVQ, IOPQ} : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET} : RRSP; 1: RNONE; # Don't write any register ]1
2
3
4
5写回阶段
dstM的 HCL 描述word dstM = [ icode in {IMRMOVQ, IPOPQ} : rA; 1: RNONE; # Don't write any register ]1
2
3
4
执行阶段
图示
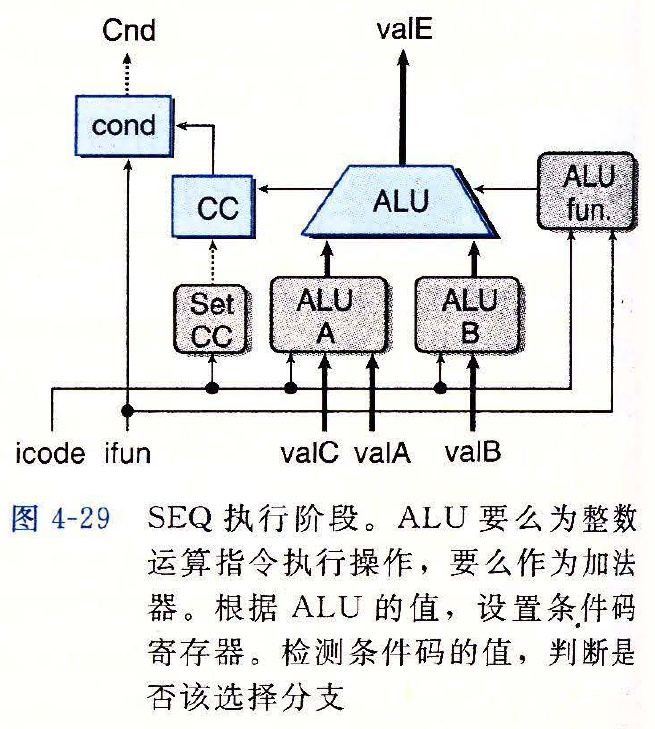
- 根据指令的类型,
aluA和aluB的取值会不同
- 根据指令的类型,
aluA的 HCL 表示word aluA = [ icode in { IRRMOVQ, IOPQ } : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ } : valC; icode in { ICALL, IPUSHQ} : -8; icode in { IRET, IPOPQ} : 8; # Other instructions don't need ALU ]1
2
3
4
5
6
7aluB的 HCL 表示word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, IPUSHQ, IPOPQ, ICALL, IRET} : valB; icode in { IRRMOVQ, IIRMOVQ} : 0; # Other instructions don't need ALU ]1
2
3
4
5ALU 控制的 HCL 表示为
word alufun = [ icode == IOPQ: ifun; 1: ALUADD; ]1
2
3
4使用
set_cc来控制是否该更新寄存器bool set_cc = icode in {IOPQ}1
访存阶段
示意图
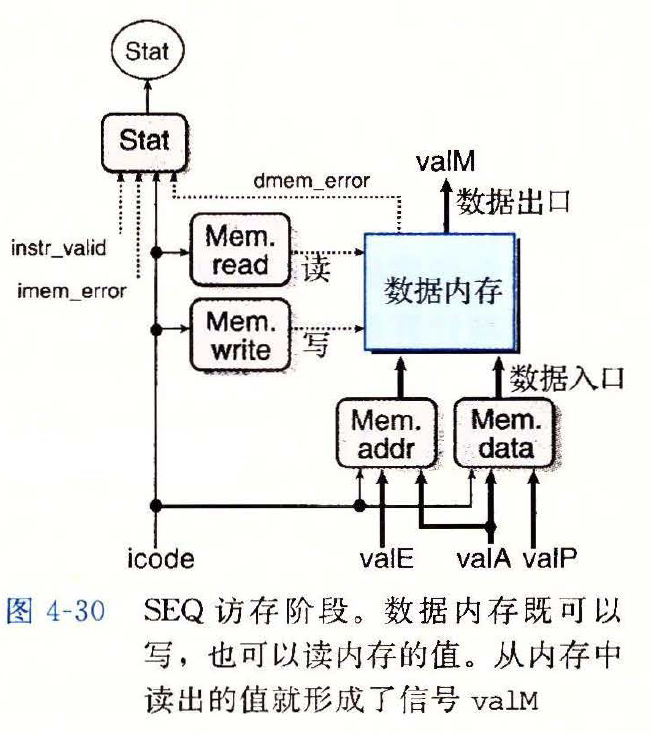
内存读和写的地址总是
valE或valAmem_addr的 HCL 描述word mem_addr = [ icode in {IRMMOVQ, IMRMOVQ, IPUSHQ, ICALL}: valE icode in {IPOPQ, IRET}: valA # Other instructions don't need address ]1
2
3
4
5mem_data的 HCL 描述word mem_data= [ icode in {IRMMOVQ, IPUSHQ}: valA icode == ICALL: valP # Other instructions don't need data ]1
2
3
4
5mem_read的 HCL 描述bool mem_read = icode in { IMRMOVQ, IPOPQ, IRET };1mem_write的 HCL 描述bool mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL};1stat的 HCL 描述bool stat = [ imem_error || dmem_error: SADR; !instr_valid: SINS; icode == IHALT: SHLT; 1: SAOK; ]1
2
3
4
5
6
访存阶段
示意图
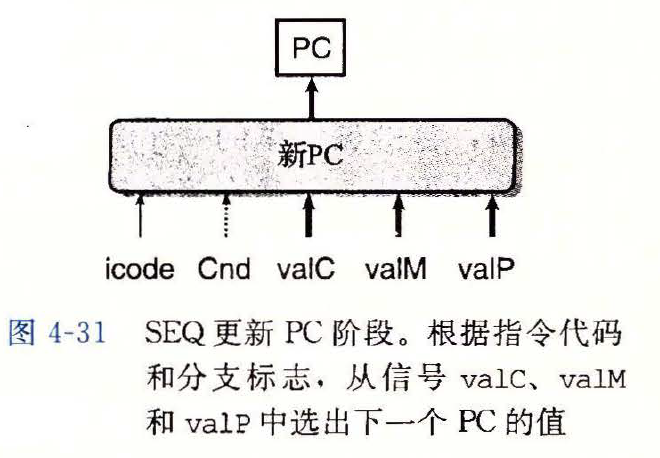
new_pc的 HCL 描述word new_pc = [ icode == ICALL : valC; icode == IJXX && Cnd : valC; icode == IRET: valM; 1: valP; ]1
2
3
4
5
6
SEQ 小结
- 通过将执行每条不同指令所需的步骤组织成一个统一的流程,就可以用很少量的各种硬件以及一个时钟来控制计算的顺序,从而实现整个处理器
- SEQ 的时钟必须非常慢,以使信号能在一个周期内传播所有的阶段
- 这种实现方法不能充分的利用硬件
- 因为每个单元只在整体时钟周期的一部分时间内才被使用
引入流水线可以获得更好的性能
# 4.4 流水线的通用原理
流水线化的特点
- 在流水线化的系统中,待执行的任务被划分成了若干个独立的阶段
- 流水线能够提高系统的吞吐量(throughput)
- 流水线会轻微的增加系统的延迟(latency)
# 4.4.1 计算流水线
吞吐量与延迟
- 电路延迟以皮秒(picosecond, 简写为 ps),即
秒来计算 - 以每秒千兆条指令(GIPS)为单位来描述吞吐量
- 即为每秒十亿条(
)指令
- 即为每秒十亿条(
- 从头到尾执行一条指令所需的时间称为延迟
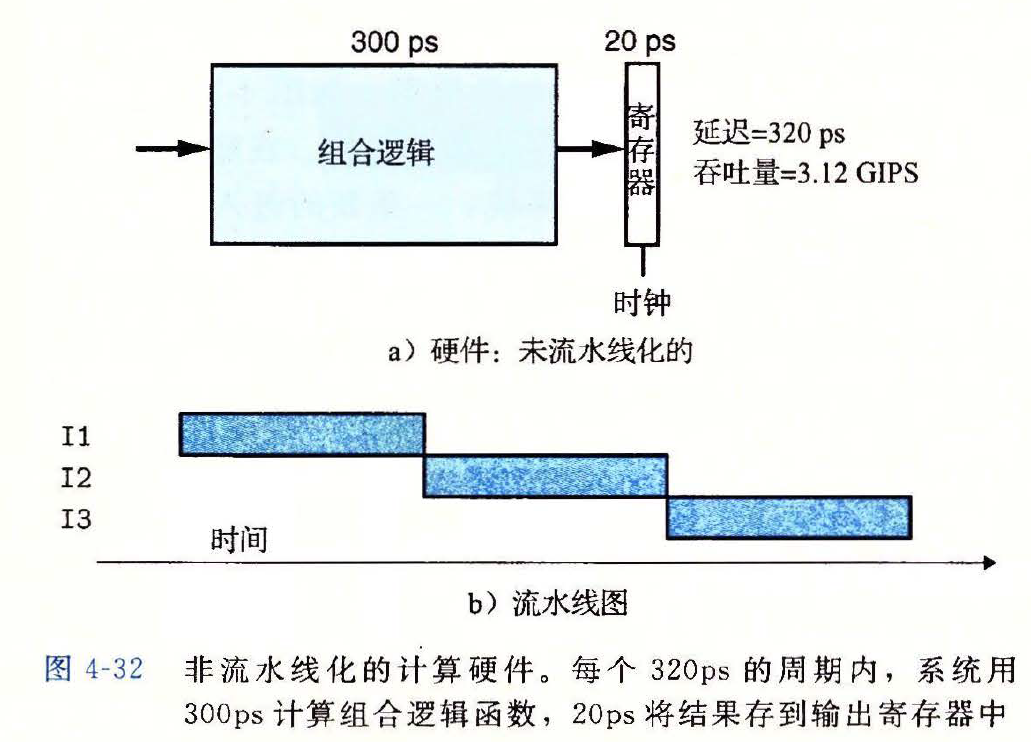
非流水线化与流水线化的计算硬件
- 非流小线化的计算硬件
图示
- 流水线化的计算硬件
图示
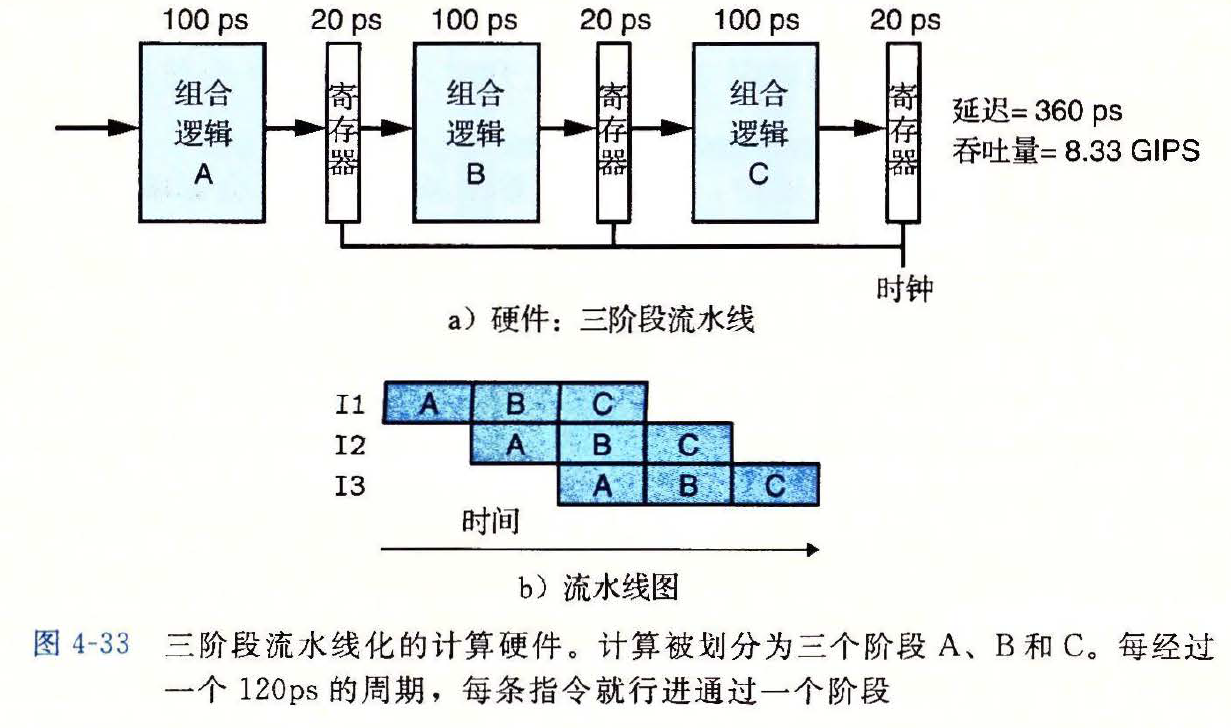
- 在稳定状态下,流水线的每个阶段都应该是活动的
- 即每个时钟周期,都有一条指令离开系统,并且有一条新的指令进入系统
流水线能够提高系统的吞吐量,但是代价是增加了一些硬件,以及延迟的增加
- 延迟变大是由于增加的流水线寄存器的时间开销
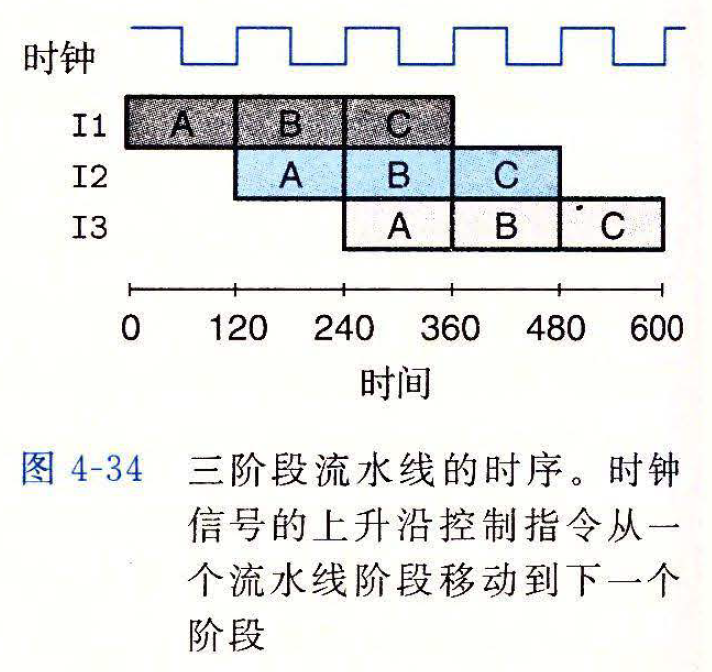
# 4.4.2 流水线操作的详细说明
流水线阶段之间的指令转移是由时钟信号来控制的
图示
流水线操作的一个时钟周期
图示
.jpg)
- 信号可能以不同的速度通过各个不同的部分
在组合逻辑块之间采用时钟寄存器的简单机制,足够控制流水线中的指令流
- 随着时钟周而复始地上升和下降,不同的指令会通过流水线的各个阶段,不会相互干扰
# 4.4.3 流水线的局限性
不一致的划分
图示
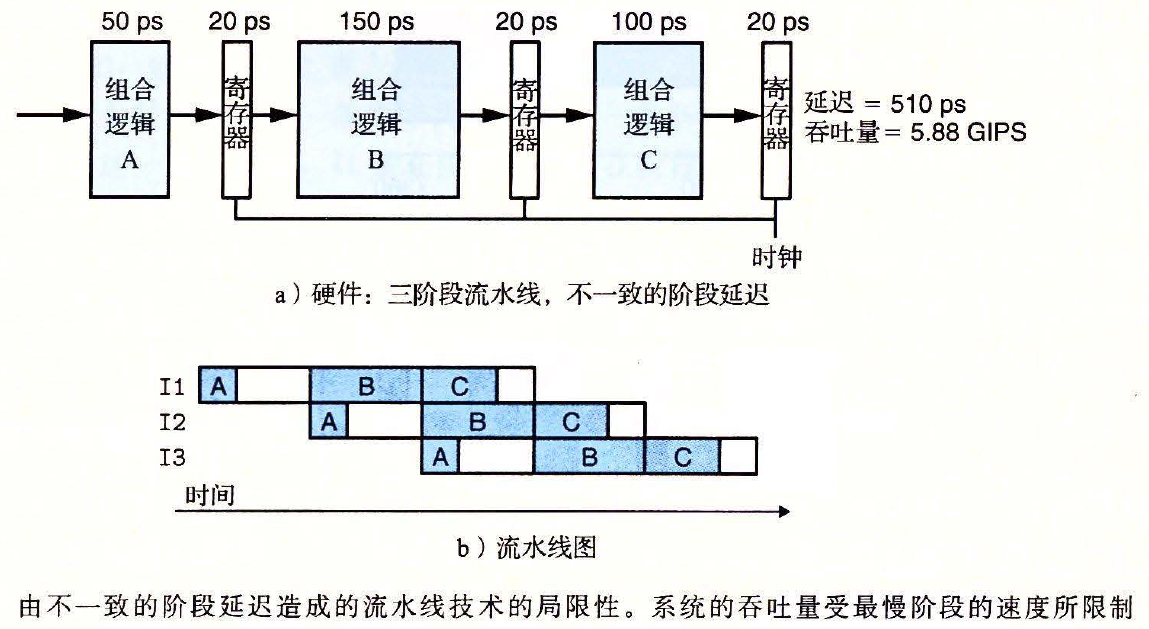
- 系统的吞吐量和延迟受最慢阶段的速度所限制
流水线过深
图示
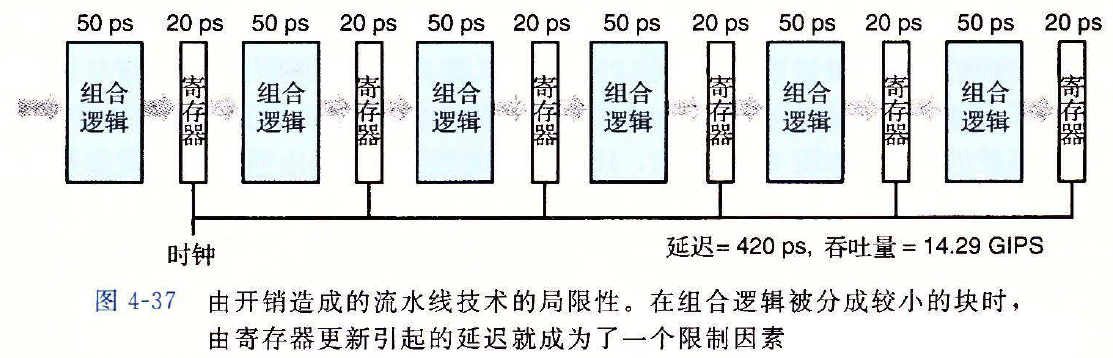
- 流水线过深时
- 寄存器延迟会成为限制流水线吞吐量的一个制约因素
- 系统的延迟也会相应的增加
# 4.4.4 带反馈的流水线系统
传过流水线的对象,可能不是相互独立的
- 相邻的指令之间可能存在着 数据相关
下一条指令会用到当前指令的计算结果
实例
irmovq $50, %rax addq %rax , %rbx mrmovq 100(%rbx ), %rdx1
2
3图示
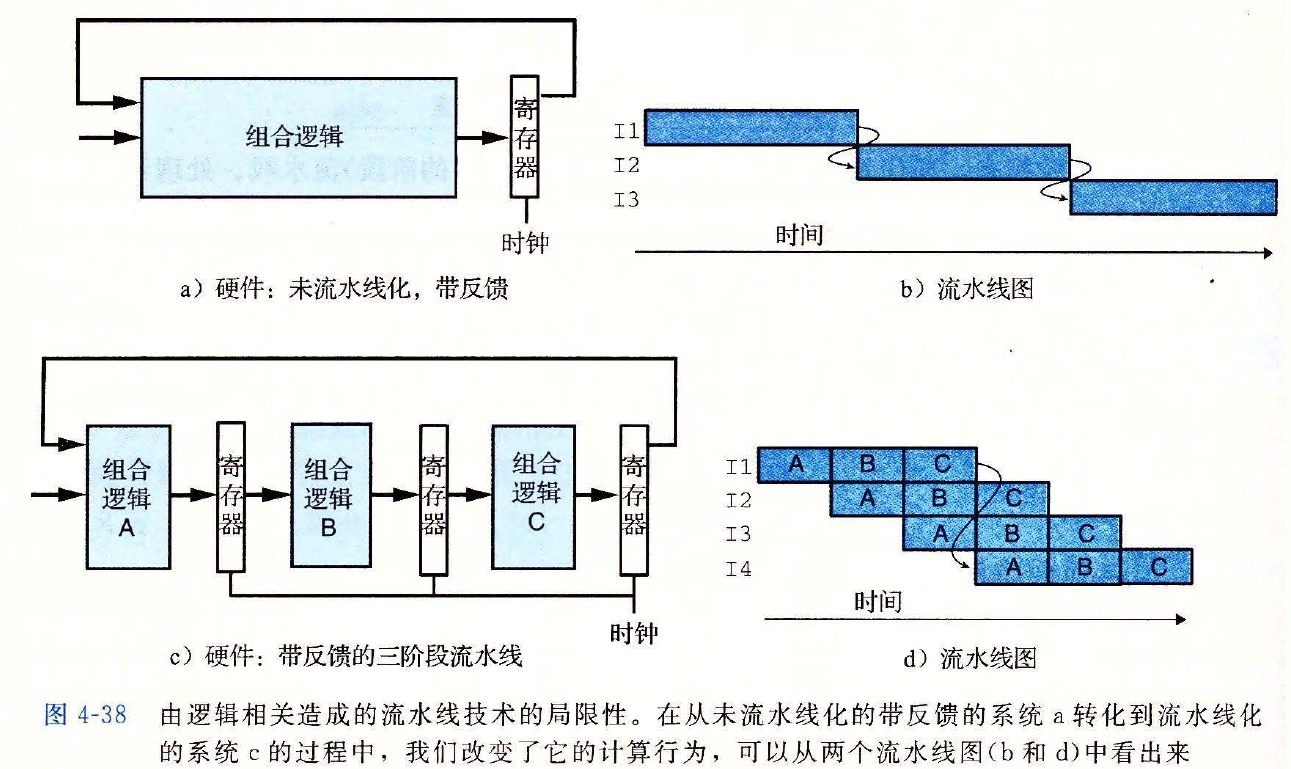
- 由于指令控制流造成的 控制相关
- 一条指令会确定下一条指令的位置
# 4.5 Y86-64 的流水线实现
# 4.5.1 SEQ+: 重新安排计算阶段
改变计算 PC 的位置
- 改进前SEQ 的硬件结构
改进后的 SEQ+ 硬件结构图示
- 根据前一个周期产生的控制信号等信息来计算 PC
- 这种对状态单元的改变称为电路重定时
- 重定时改变了一个系统的状态表示,但是并不改变它的逻辑行为
- 通常用其来平衡一个流水线系统中各个阶段之间的延迟
.jpg)
# 4.5.2 插入流水线寄存器
在 SEQ+ 的各个阶段之间插入流水线寄存器
- 每个流水线寄存器可以存放多个字节和字
- 各个流水线寄存器的作用
F- 保存程序计数器的预测值
D- 位于取指和译码阶段之间
- 保存关于最新取出的指令的信息
E- 位于译码和执行阶段
- 保存最新的译码指令和从寄存器文件读出的值的信息
M- 位于执行和访存阶段之间
- 保存最新执行的指令的结果;还保存用于处理条件转移的分支条件和分支目标的信息
W- 位于访存阶段和反馈路径之间
#
PIPE- 的硬件结构图示
.jpg)
指令通过流水线的示例
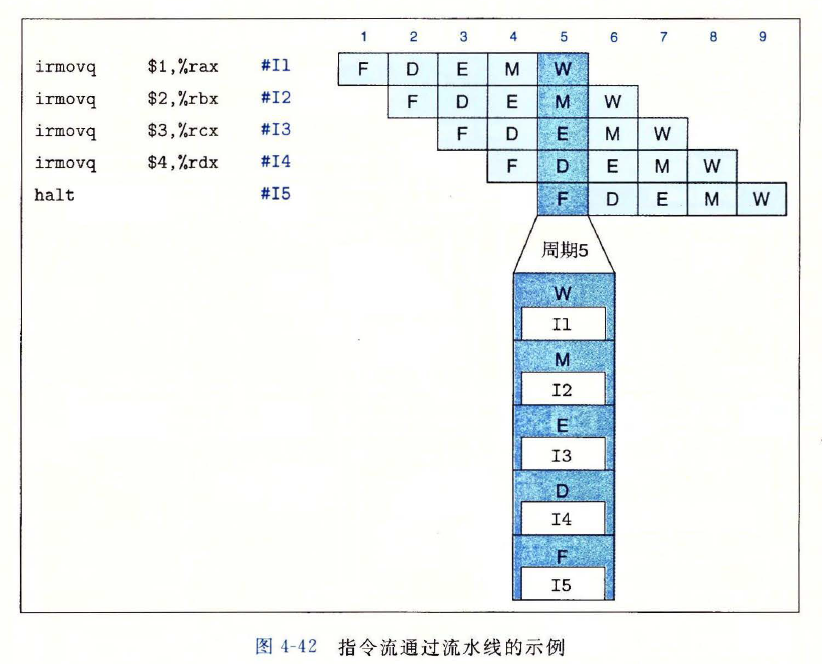
# 4.5.3 对信号进行重新排列和编号
信号编号规则
- 在流水线化的设计中,与各个指令相关联的值有多个版本,会随着指令一起流过系统
- 存储在流水线寄存器中的信号,通过在信号名前加上大写的流水线寄存器名字作为前缀
- 如
D_stat、E_stat
- 如
- 在某一个阶段刚计算出来的信号,其命名是在信号名前面加上小写的阶段名第一个字母作为前缀
- 如
f_stat、m_stat
- 如
#
Select A 块
- 参照 PIPE- 硬件结构图
- 其会从
D_valP和d_rvalA中选择一个信号传送给E_valA- 只有
call在访存阶段和jxx指令在执行阶段(当不需要跳转时)需要valP的值- 而这些指令不需要从寄存器中读出的值
jxx指令默认是选择跳转分支,即valC的值,参照 4.5.4 预测下一个PC
- 只有
- 包括这个块是为了减少要传递给寄存器
E和M的状态数量
# 4.5.4 预测下一个 PC
流水线设计的目的就是每个时钟周期都发射一条新指令
- 因此必须在取出当前指令后,马上确定下一条指令的位置
- 但如果取出的是条件分支指令,则必须要等到条件分支指令通过执行阶段后,才能知道是否要选择分支
- 如果取出的指令是
ret,则要到指令通过访存阶段,才能确定返回地址
分支预测
- 猜测分支方向并根据猜测开始取指的技术称为分支预测
- 有些系统花费了大量的硬件来解决这个问题
- PIPE- 采用总是预测选择了条件分支(always taken)的简单策略
- 这个策略的成功概率有 60%
- 从不选择(never taken, NT)
- 这个策略成功的概念有 40%
- 反向选择,正向不选择(backward taken, forward not-taken)
- 当分支的地址比下一条指令低时,就选择分支;否则不选择
- 成功率有 65%
- 因为循环往往由后向分支结束,而循环往往要执行很多次
必须有措施来应对预测错误的情况
- 分支预测错误会极大的降低程序的性能,因此在条件允许时,往往用条件数据传送来替代条件控制转移
返回地址预测
- PIPE- 中不对返回地址作任何预测,只是简单地暂停处理新指令,直至
ret指令通过写回阶段 使用硬件栈进行返回地址预测
- 因为一般情况下,过程调用和返回是成对出现的,因此可以在取指阶段,用一个硬件栈来储存过程调用指令产生的返回地址
- 当碰到
ret指令时,就从栈中弹出顶部的值,作为预测的返回地址 - 在预测错误时,必须要有相应的错误恢复机制
此硬件栈对于程序员来说是不可见的
# 4.5.5 流水线冒险
数据相关和控制相关可能会导致流水线出现计算错误,称为冒险(hazard)
- 数据相关和控制相关参照 带反馈的流水线系统
- 冒险分为数据冒险和控制冒险
数据冒险
- 如果一个指令的操作数被它前面三条指令中的任意一个改变的话,都会出现数据冒险
- 相当于当前指令处于译码阶段时,在流水线的执行,访存和写入阶段中的其它指令对当前指令的操作数进行修改
- 此处主要是指寄存器数据冒险
数据冒险示例
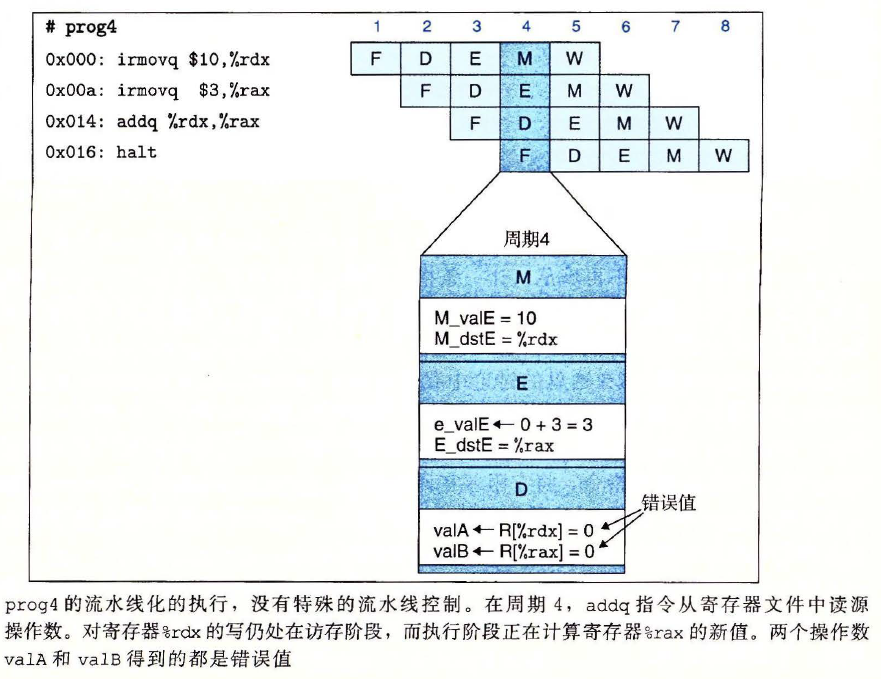
用暂停来避免数据冒险
- 暂停 (stalling) 是避免冒险的一种常用技术
- 暂停技术就是让一组指令阻塞在它们所处的阶段,而允许其他指令继续通过流水线
- 让一条指令停留在译码阶段,直至修改它源操作数的指令通过了写回阶段,就可以避免数据冒险
- 还需将其下一条指令阻塞在取指阶段,通过保持 PC 值不变可以做到这一点
- 将指令阻塞在译码阶段,就是在执行阶段插入一个气泡(bubble)
- 气泡像一个自动产生的
nop指令 -- 它不会改变寄存器、内存、条件码或程序状态
- 气泡像一个自动产生的
示例
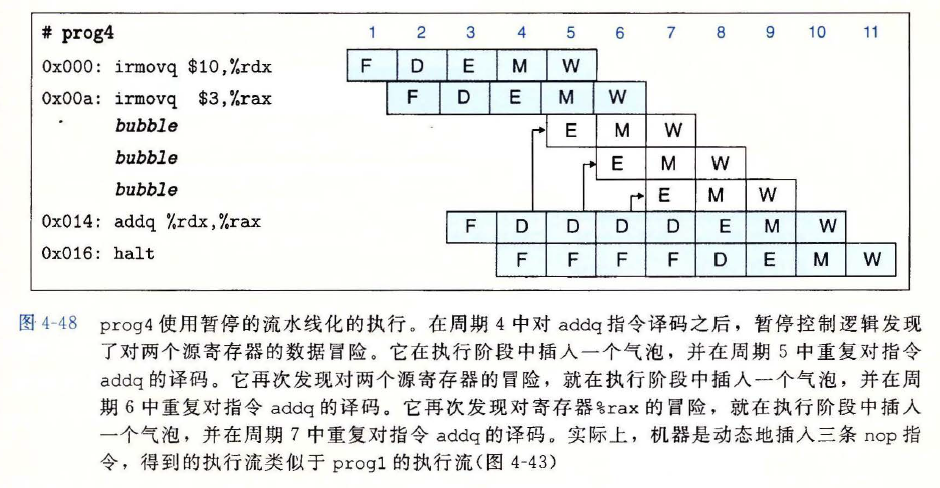
用暂停获得的性能并不很好,因为这样会导致流水线暂停长达三个周期,会降低整体的吞吐量
用转发来避免数据冒险
- 与其暂停直到其它指令的写入操作完成,不如简单的将要写的值传到流水线操作数
E作为源操作数 - 将结果值直接从一个流水线阶段传送到较早阶段的技术称为数据转发(data forwarding,或简称转发,有时称旁路(bypassing))
- 数据转发需要在基本的硬件结构中增加一些额外的数据连接和控制逻辑
- 在写入阶段,访存阶段和执行阶段有对寄存器未进行的写时,均可以使用数据转发
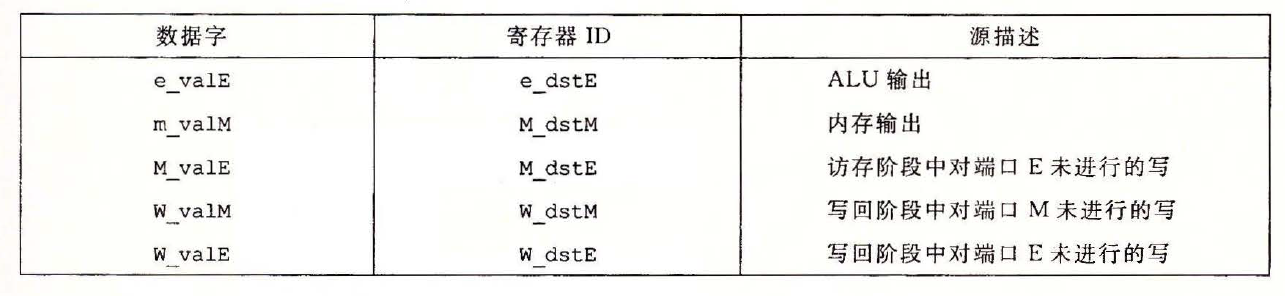
- 一共有 5 个不同的转发源 (
e_valE,m_valM,M_valE,W_valM和W_valE) 实例
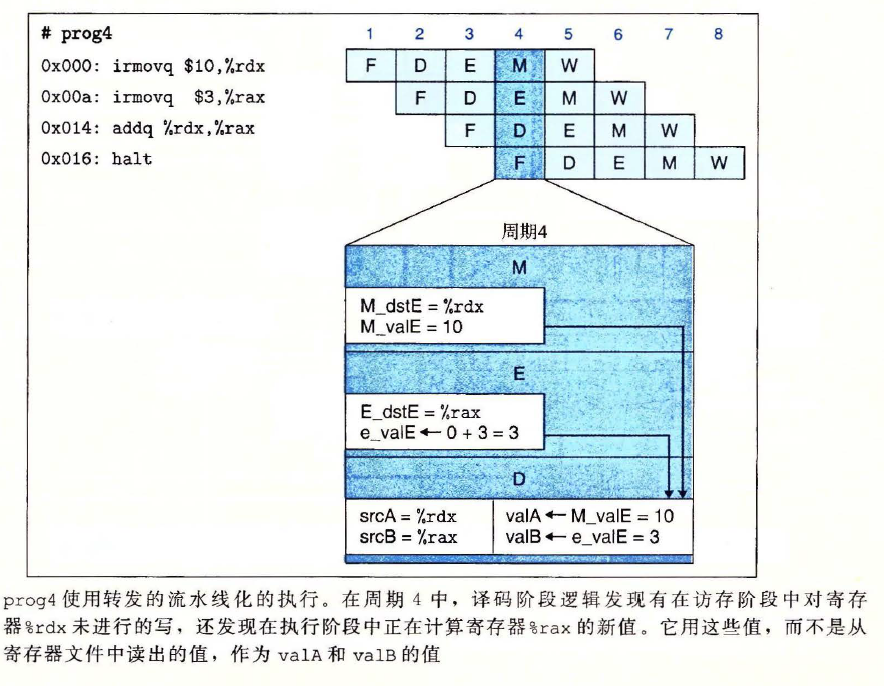
- 译码阶段逻辑能够确定是使用来自寄存器文件的值,还是用转发过来的值
- 通过
e_dstM,M_dstE,M_dstM和W_destE,W_destM的值与源寄存器 IDsrcA和srcB相比较,能够确定是否使用转发的值 - 不过有多个流水线寄存器的值和源 ID 相等时,需要在各外转发源中建立起优先级关系
- 具体参照译码和写回阶段
- 通过
- 与其暂停直到其它指令的写入操作完成,不如简单的将要写的值传到流水线操作数
加载/使用数据冒险
- 由于访存要比译码晚两个阶段,当需要从内存中读取数据更新寄存器
%rax的值,而下一条指令又需要%rax的值时,就会出现加载/使用数据冒险 加载/使用冒险示例
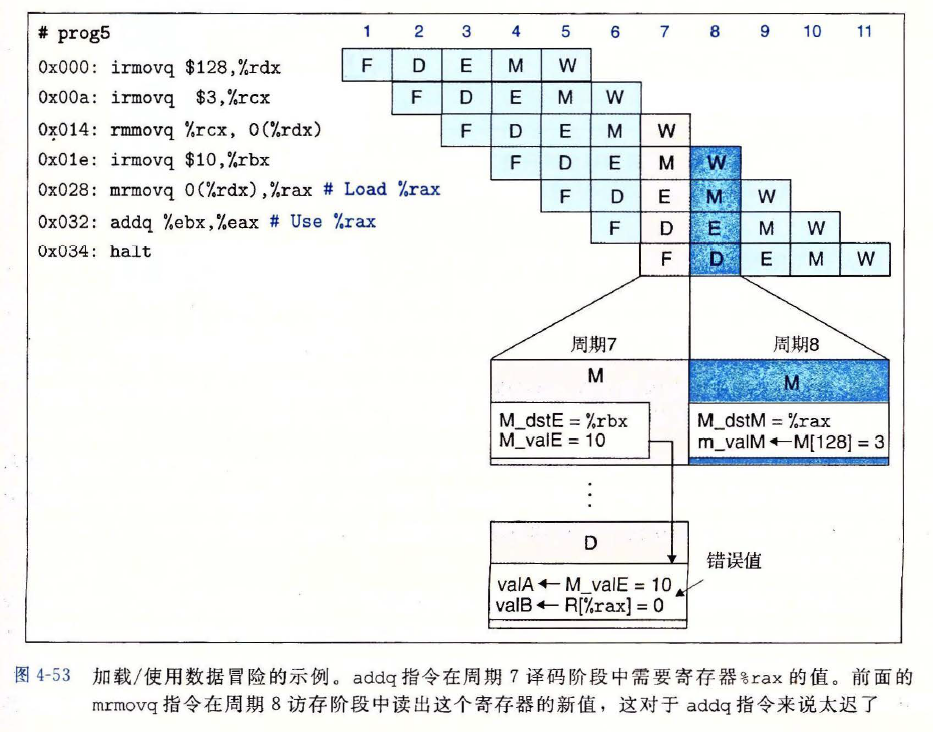
- 将暂停和转发结合起来,可以避免加载/使用数据冒险
- 这种方法称为加载互锁(load interlock)
用加载互锁来处理加载/使用冒险的实例
.jpg)
- 由于访存要比译码晚两个阶段,当需要从内存中读取数据更新寄存器
加载互锁和转发技术结合起来足以处理所有可能类型的数据冒险
- 只有加载互锁会降低流水线的吞吐量
- 因此几乎可以实现每个时钟周期发射一条新指令的吞吐目标
#
流水线化的最终实现 -- PIPE 的硬件结构
.jpg)
控制冒险
- 当处理器无法根据取指阶段的当前指令来确定下一条指令的地址时,就会出现控制冒险
ret指令的处理- 当
ret指令经过译码、执行和访存阶段时,流水线应该暂停 示例
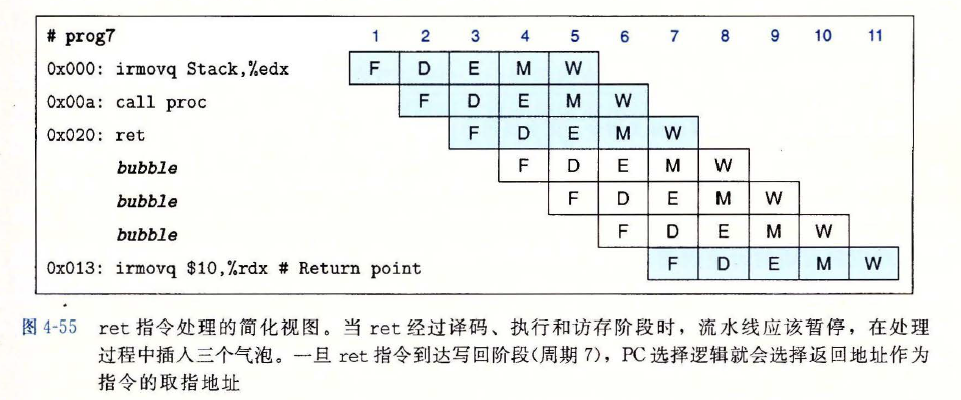
- 当
#
分支预测错误的处理
- 跳转代码在执行阶段才能发现分支预测错误,此时已经取出了两条错误指令
- 但是这两条错误指令还没有到达执行阶段,不会导致程序员可见的状态发生改变
- 只需在下一个周期向译码和执行阶段插入气泡,同时取出跳转指令后面的指令即可
示例
- 跳转代码在执行阶段才能发现分支预测错误,此时已经取出了两条错误指令
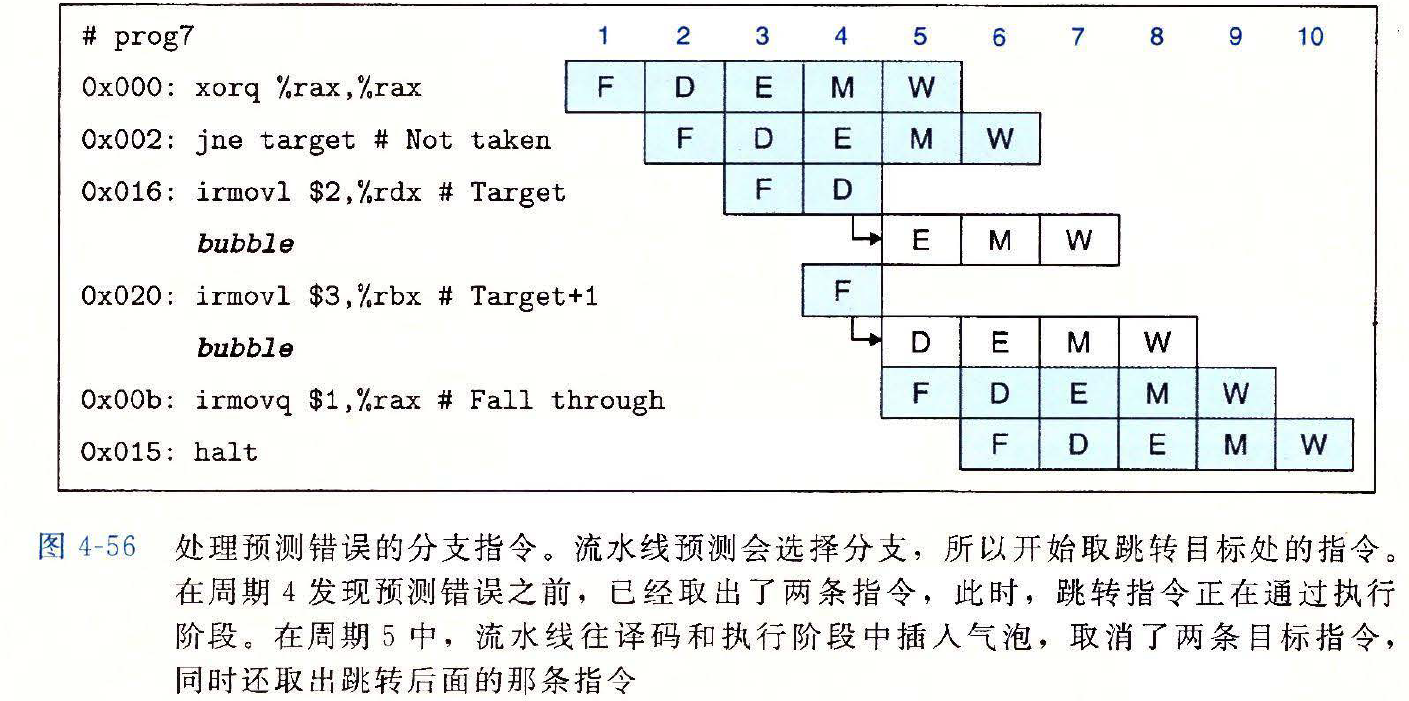
在出现特殊情况时,暂停和往流水线中插入气泡的技术可以动态调整流水线的流程
# 4.5.6 异常处理
异常处理的细节问题
可能同时有多条指令会引起异常
- 基本原则是:由流水线中最深的指令引起的异常,优先级最高
当首先取出一条指令,开始执行时,导致了一个异常,而后来由于分支预测错误,取消了该指令
示例
流水线化的处理器会在不同的阶段更新系统状态的不同部分,一条指令发生异常后,它后面的指令可能在异常完成之前改变了部分程序员可见的状态
示例


异常状态以及与指令相关的所有其他信息一起通过流水线的简单原则是处理异常的简单可靠的机制
- 每个流水线寄存器都有一个状态码
stat- 如果一个指令在其处理的某个阶段发生了异常,就会将这个状态字段设置成指示异常的种类
- 异常状态和该指令的其他信息一起沿着流水线传播,直到它到达写回阶段
- 当处于访存或写回阶段中的指令导致异常时,流水线控制逻辑必须禁止更新条件码寄存器或数据内存
- 除此之外,异常事件不会对流水线中的其他指令流有任何影响,直至异常指令到达最后的流水线阶段
- 第一条遇到异常的指令会第一个到达写回阶段,此时程序执行会停止,流水线寄存器 W 中的状态码会被记录为程序状态
- 如果取出了某条指令,过后又取消了,则所有关于这条指令的异常状态信息也会被取消
# 4.5.7 PIPE 各阶段的实现
PIPE 是使用了转发技术的流水线化的 Y86-64 处理器
PC 选择和取指阶段
PIPE 的 PC 选择和取指逻辑图
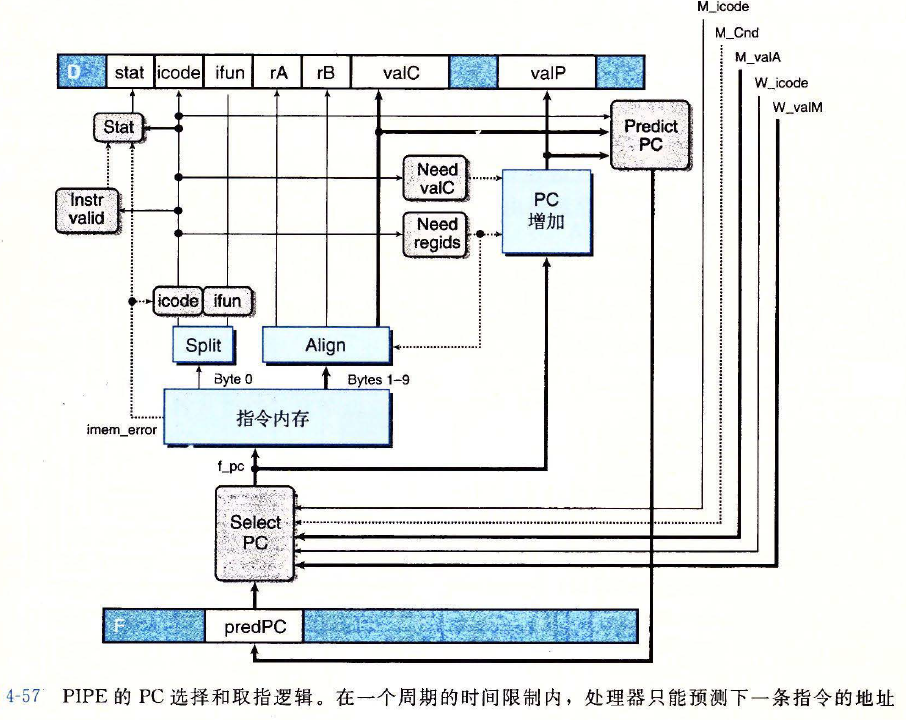
相关信号的 HCL 代码
f_pcword f_pc = [ # Mispredicted branch. Fetch at incremented PC M_icode == IJXX && !M_Cnd : M_valA; # Completion of RET instruction W_icode == IRET : W_valM; # Default: Use predicted value of PC 1 : F_predPC; ];1
2
3
4
5
6
7
8IJXX情况下选取参照 Select A块
f_predPCword f_predPC = [ f_icode in { IJXX, ICALL } : f_valC; 1 : f_valP; ];1
2
3
4jxx指令默认选择跳转分支
f_stat# Determine status code for fetched instruction word f_stat = [ imem_error: SADR; !instr_valid : SINS; f_icode == IHALT : SHLT; 1 : SAOK; ];1
2
3
4
5
6
7
#
译码和写回阶段
译码和写回阶段逻辑图
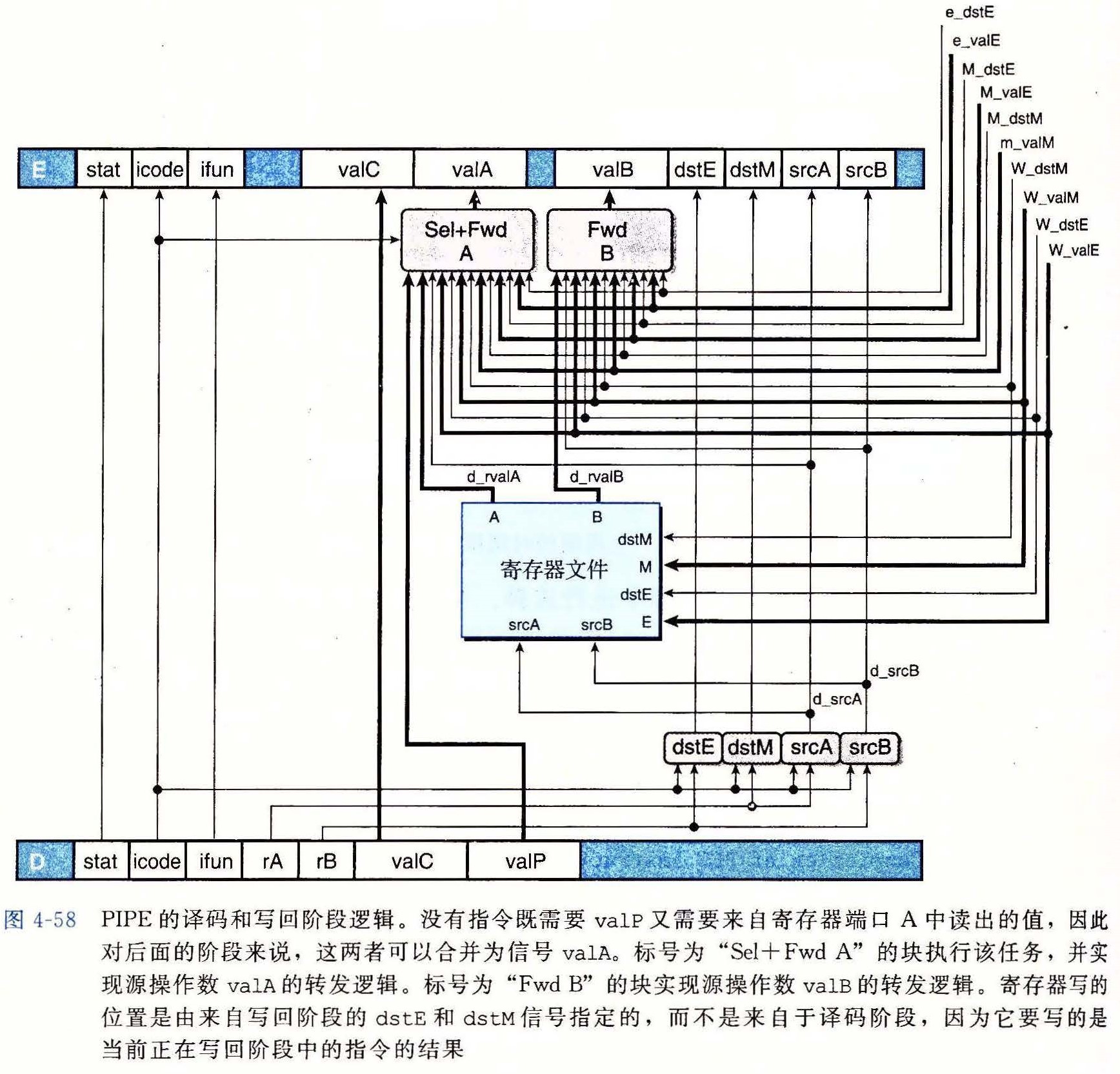
5 个不同的转发源
- 转发源的优先级依次降低
- 给处于较早流水线阶段中的转发源以较高的优先级
优先级示例程序
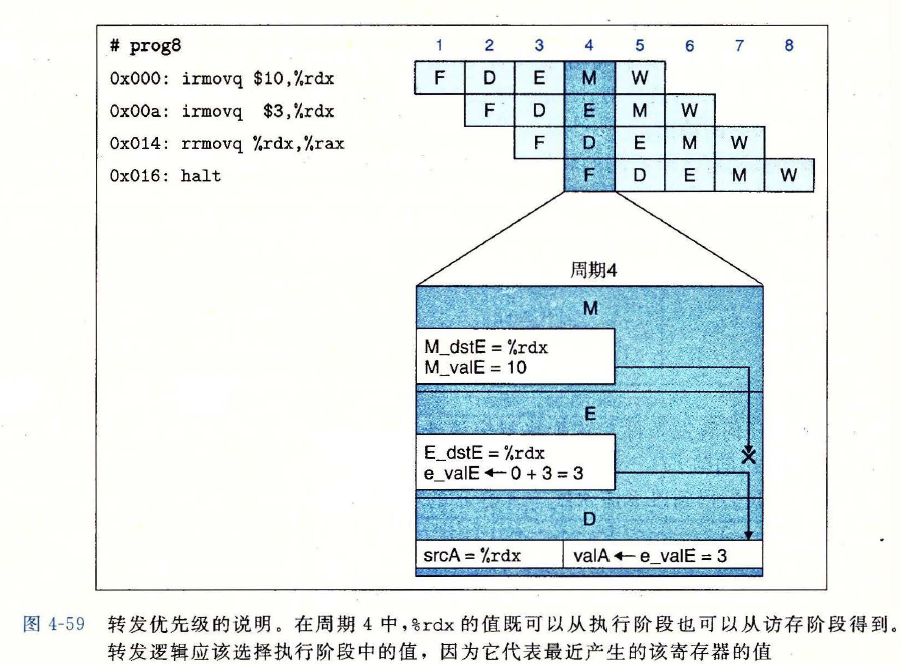
- 转发源的优先级依次降低
相关信号的 HCL 代码
d_valAword d_valA = [ D_icode in { ICALL, IJXX } : D_valP; # Use incremented PC d_srcA == e_dstE : e_valE; # Forward valE from execute d_srcA == M_dstM : m_valM; # Forward valM from memory d_srcA == M_dstE : M_valE; # Forward valE from memory d_srcA == W_dstM : W_valM; # Forward valM from write back d_srcA == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalA; # Use value read from register file ];1
2
3
4
5
6
7
8
9- 次序决定了转发源的优先级以及程序的行为
- 特别是对于
popq %rsp这种指令来说
- 特别是对于
- 次序决定了转发源的优先级以及程序的行为
d_valBword d_valB = [ d_srcB == e_dstE : e_valE; # Forward valE from execute d_srcB == M_dstM : m_valM; # Forward valM from memory d_srcB == M_dstE : M_valE; # Forward valE from memory d_srcB == W_dstM : W_valM; # Forward valM from write back d_srcB == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalB; # Use value read from register file ];1
2
3
4
5
6
7
8
执行阶段
执行阶段逻辑图
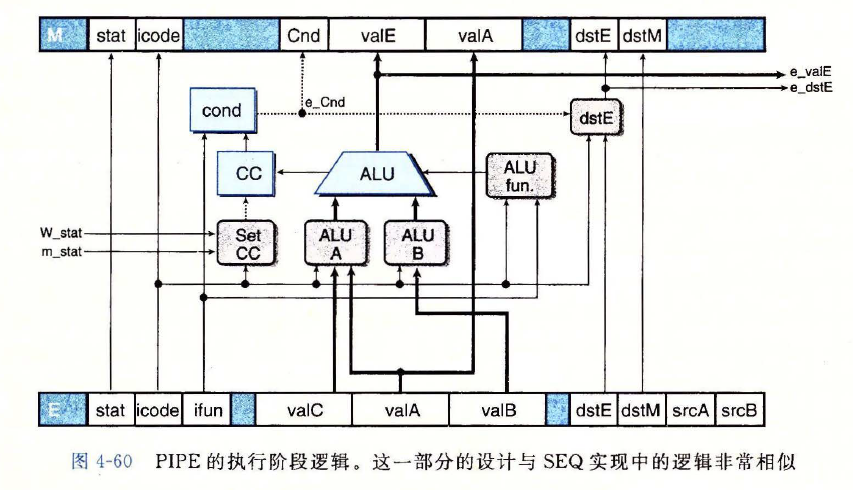
SetCC以m_stat和W_stat作为输入,来决定是否更新条件码- 这些信号用来检查是否有一条导致异常的指令正在通过后面的流水线阶段
访存阶段
图示
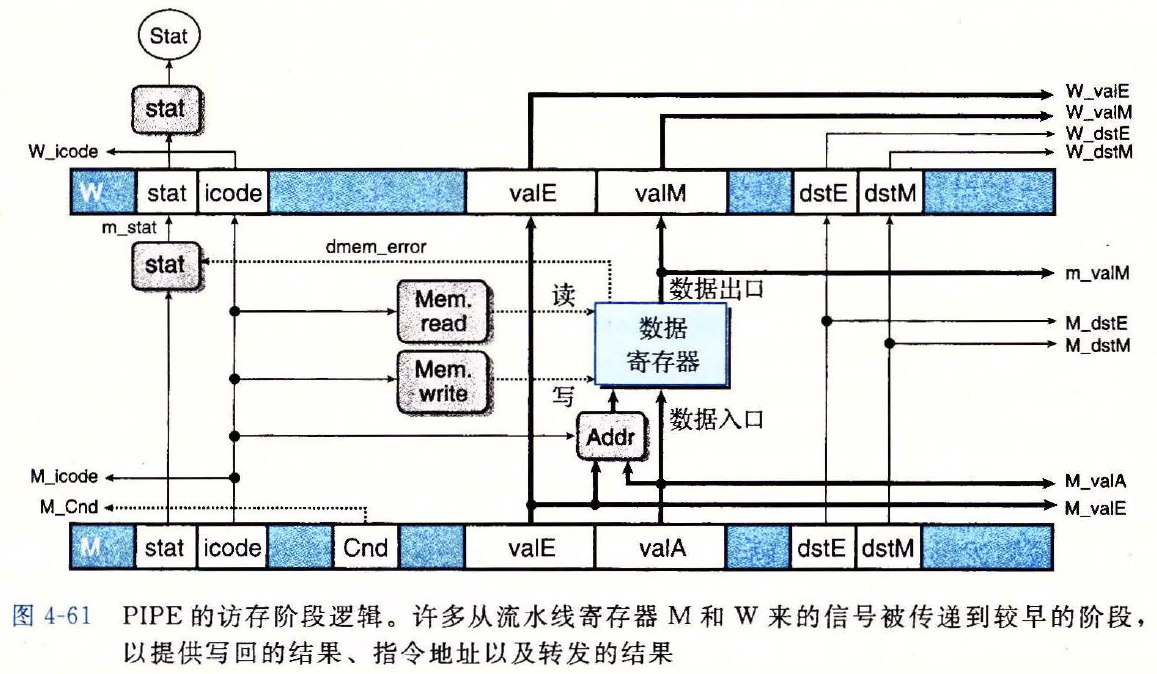
相关信号的 HCL 代码
f_stat# Determine status code for fetched instruction word m_stat = [ dmem_error: SADR; 1 : M_stat; ];1
2
3
4
5
# 4.5.8 流水线控制逻辑
4 种特殊的控制情况
- 加载/使用冒险
- 在从内存中取值的指令和使用该值的指令之间,流水线需要暂停一个周期
- 处理
ret- 流水线需暂停直到
ret指令到达写回阶段
- 流水线需暂停直到
- 预测错误的分支
- 需要取消错误加载的分支,并从跳转指令后面的那条指令开始执行
- 异常
- 当一条指令导致异常,必须禁止后面的指令更新程序员可见状态,并在异常指令到达写回阶段时,停止执行
特殊情况下所期望的处理
- 只有
mrmovq,popq指令会从内存中读数据,只有在这种情况下才可能会发生加载/使用冒险- 当发现冒险情况时,需保持流水线寄存器
F和D不变,并且在执行阶段插入气泡
- 当发现冒险情况时,需保持流水线寄存器
- 流水线需要暂停 3 个周期,直到
ret指令完成访存阶段,读出返回地址,进入写回阶段ret指令的详细处理过程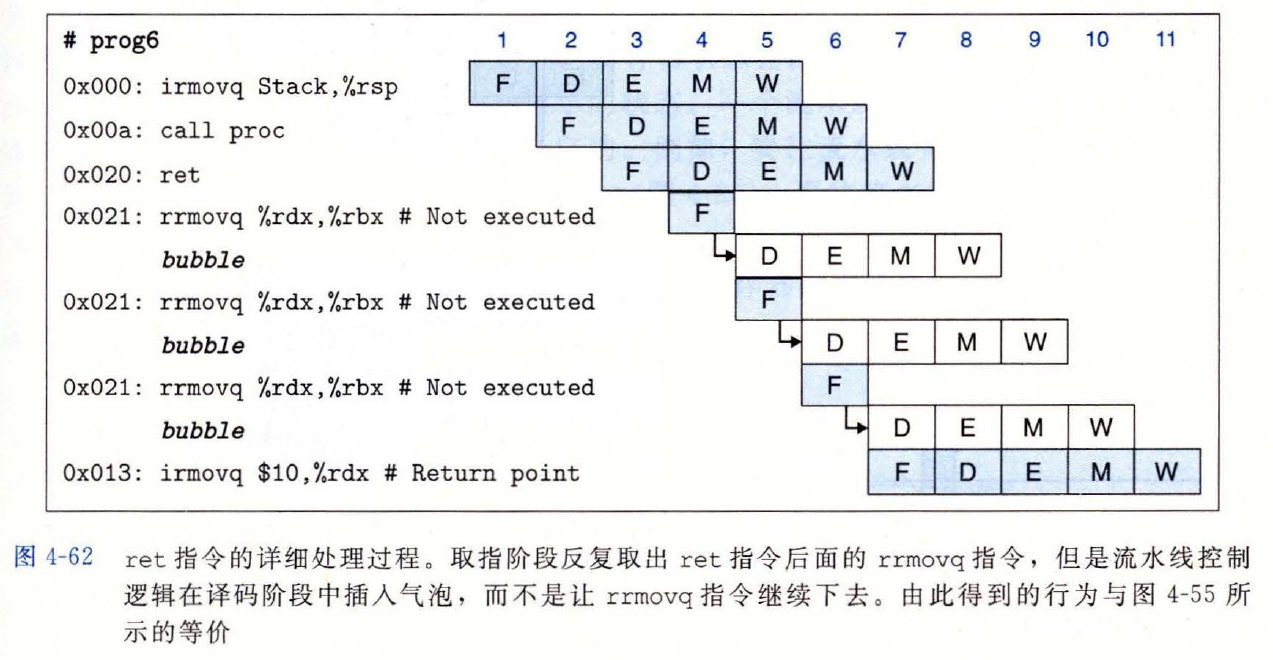
- 无法在取指阶段插入气泡,因此在译码阶段插入气泡,阻止
ret后面的一条指令继续运行
- 分支预测错误的情况参照控制冒险
- 异常处理
异常处理示例
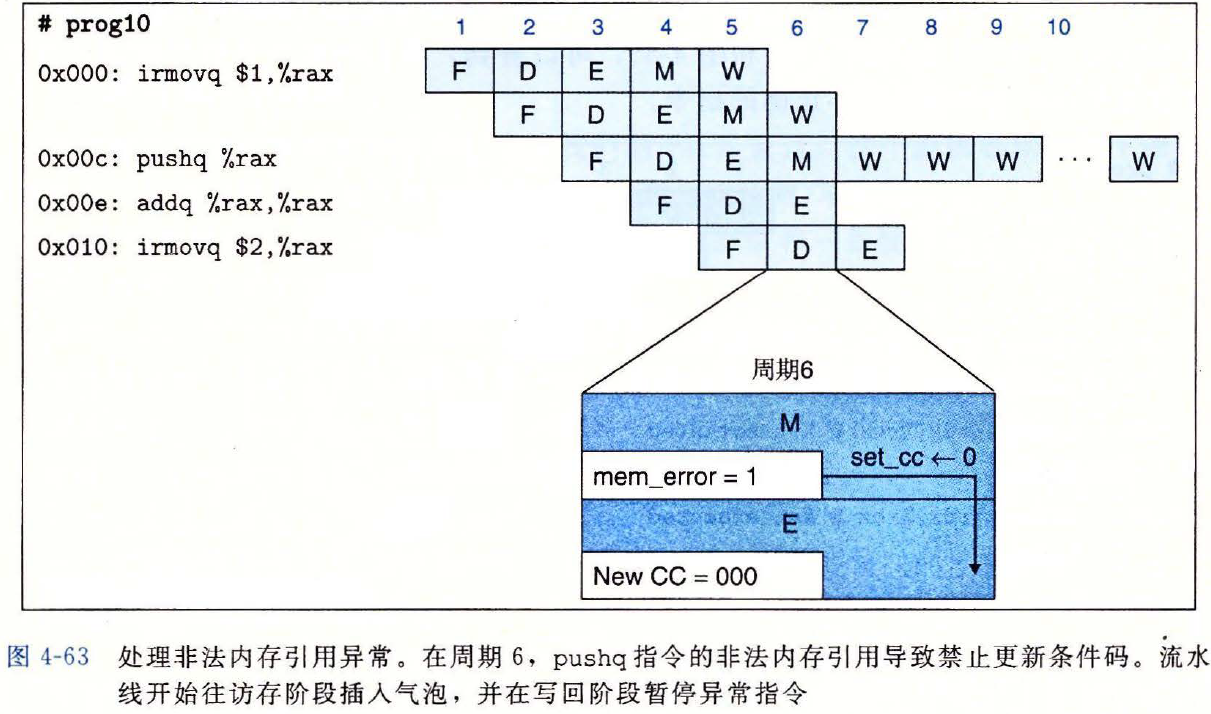
- 访存阶段出现的错误会禁止执行阶段更新条件码
- 并在访存阶段插入气泡

流水线控制机制
- 每个流水线寄存器有两个控制输入:暂停(stall) 和气泡(bubble)
- 当暂停信号设为
1时,会禁止更新状态- 使得其可以将指令阻塞在某个流水线阶段中
- 当气泡信号设置为
1时,寄存器状态会设置成某个固定的复位配置(reset configuration),得到一个等效于nop指令的状态 - 将气泡和暂停信号都设为
1看成是出错 附加的流水线寄存器操作
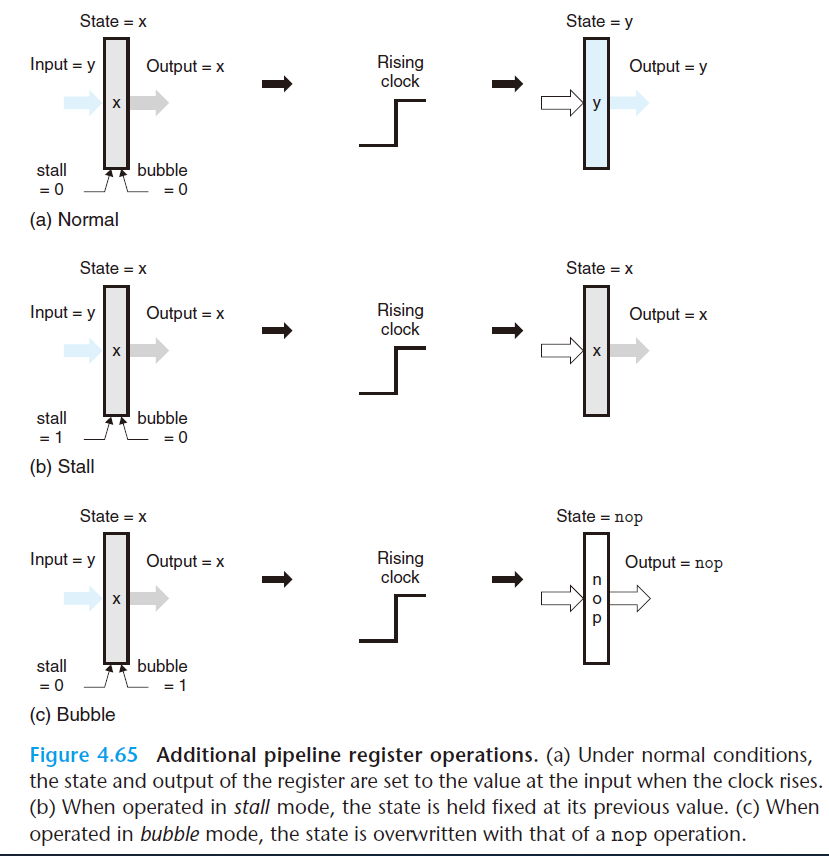
- 当暂停信号设为
- 时序方面,流水线寄存器的暂停和气泡控制信号是由组合逻辑块产生的

控制条件的组合
在设计系统时,常见的缺陷是不能同时处理多个特殊情况的情形
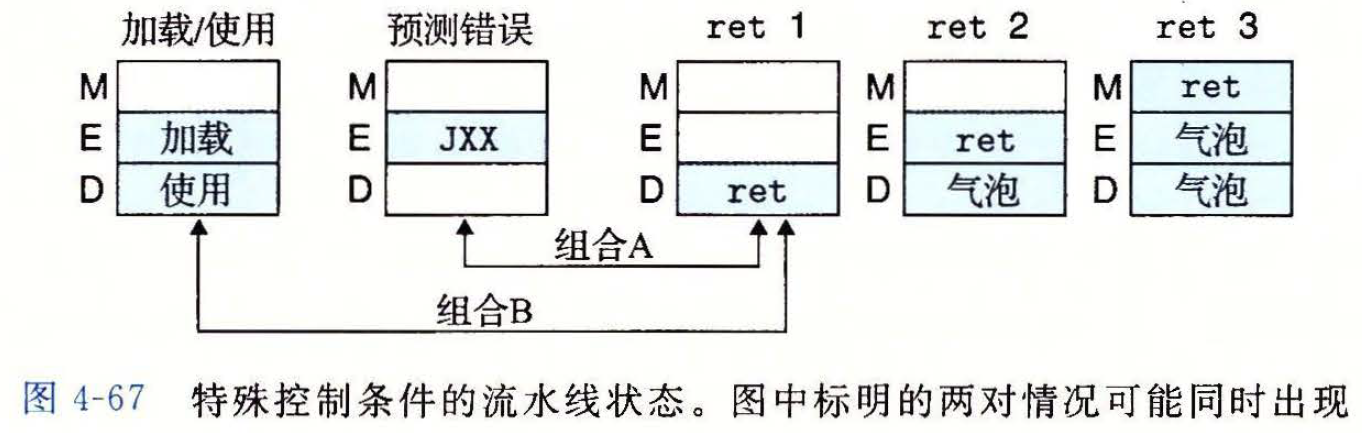
- 可能同时出现的控制条件
图示
组合
A的处理ret指令位于jxx的跳转目标处,同时jxx选择不跳转时,会出现此类情况解决方案图示

- 简单的组合两种处理情况,即可解决问题。即流水线能正常处理此种组合
组合
B的处理- 当
ret前的一条指令从内存中读取数据设置%rsp时,会出现这种情况 解决方案图示

- 简单的组合会出现气泡+暂停的问题,实际处理时应将
ret指令的动作推迟一个周期
- 当
🔲 待做事项
- 练习题 4.37 答案的具体含义
控制逻辑的实现
PIPE 流水线控制逻辑图
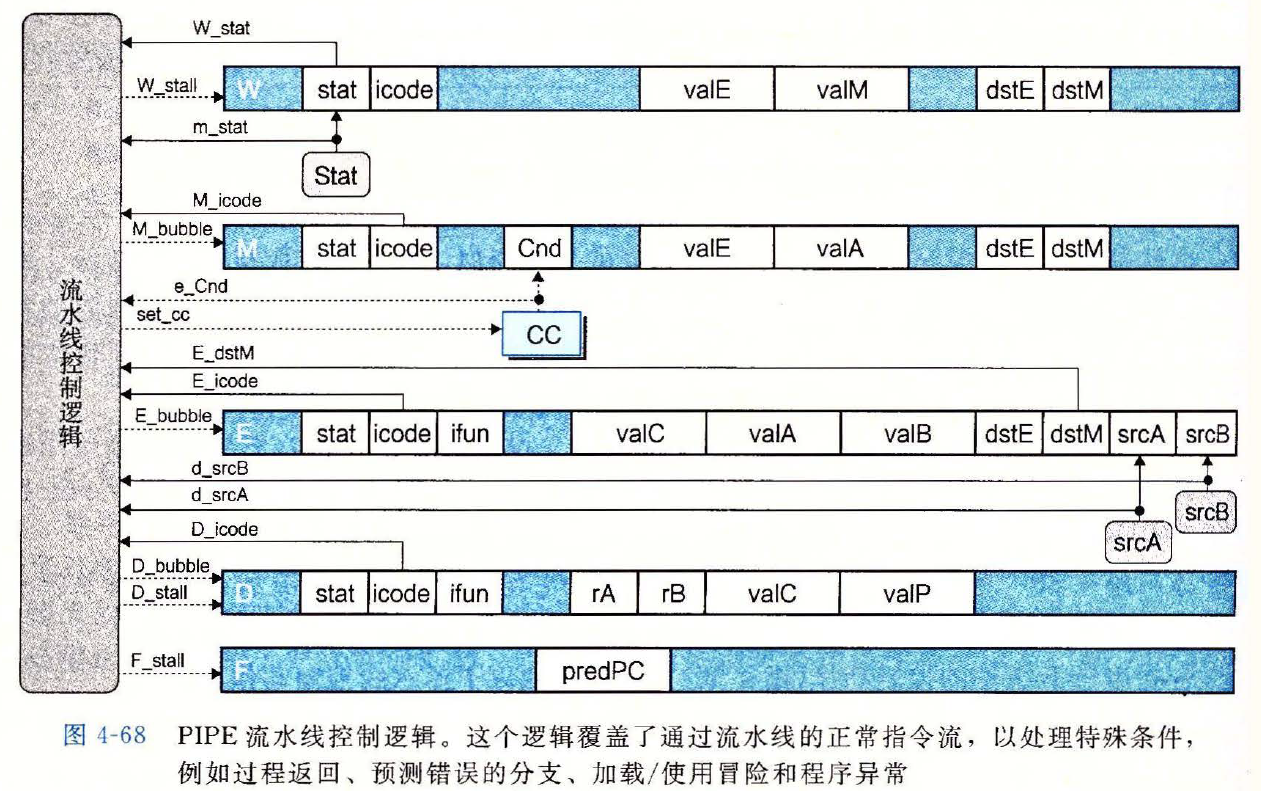
- 相关信号的
HCL代码F_stallbool F_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB } || # Stalling at fetch while ret passes through pipeline IRET in { D_icode, E_icode, M_icode };1
2
3
4
5
6D_stallbool D_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB } ||1
2
3
4D_bubblebool D_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Bubbling at fetch while ret passes through pipeline # but not condition for a load/use hazard !(E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB }) && IRET in { D_icode, E_icode, M_icode };1
2
3
4
5
6
7E_bubblebool E_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB };1
2
3
4
5
6set_ccbool set_cc = E_icode == IOPQ && # State changes only during normal operation !m_stat in { SADR, SINS, SHLT } && !W_stat in { SADR, SINS, SHLT };1
2
3M_bubblebool M_bubble = m_stat in { SADR, SINS, SHLT } || W_stat in { SADR, SINS, SHLT };1W_stallbool W_stall= W_stat in { SADR, SINS, SHLT };1
# 4.5.9 性能分析
所有需要流水线控制逻辑进行特殊处理的条件,都会导致流水线不能实现每个时钟周期发射一条指令的目标
- 可以通过确定往流水线中插入气泡的频率来衡量效率的损失
- 因为插入气泡会导致未使用的流水线周期
- 暂停往往伴随插入气泡
CPI
- CPI (Cycles Per Instruction,每指令周期数)
- 一个时间段内共处理了
条指令和 条气泡
- 一个时间段内共处理了
各种处罚汇总表

- 条件转移指令非常常见,为了进一步降低 CPI,需要提升分支预测的成功概率
# 4.5.10 未完成的工作
多周期指令
- 更为复杂的指令需要多个周期才能完成
- 一般采用独立于主流水线的特殊硬件功能单元来处理较为复杂的操作
- 一条指令在译码阶段,可以被发射到特殊单元,处理器会继续处理其它指令
- 但不同单元的操作必须同步,以避免出错
与储存系统的接口