
 学习笔记
学习笔记
# 算法基础
- 排序算法的问题描述
- Input: 序列
- Ouput: 排序后的序列
, 其中
- Input: 序列
# 插入排序
# 伪代码实现
INSERTION-SORT(A)
for j = 2 to A.length
key = A[j]
# Insert A[j] into sorted sequence A[1..j-1]
i = j - 1
while i > 0 and A[i] > key
A[i+1] = A[i]
i = i - 1
A[i+1] = key
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
- 书中的伪代码数组下标从 1 开始
# 循环不等式证明算法的正确性
- 三个步骤
- 初始化
- 保持
- 终止
- 类似于数学归纳法
# 算法的性能分析
- 分析算法通常意味着预测算法需要的资源,通常度量的是计算时间
- 度量的规则
- 使用单处理器计算模型--随机访问机( RAM ), 在 RAM 模型中,指令一条接一条的执行,没有并发操作
- 常见的指令:算术指令(加法,减法,乘法,除尘,取余,向下取整,向上取整),数据移动指令(装入,存储,复制)和控制指令(条件与无条件转移、子程序调用与返回)。每条此种类型的语句,度量时间为常量
# 播入排序的算法分析
- 分析每条语句的执行次数

- 然后将总的代价相加,即可得到总的运行时间
- 性能一般与输入有关
- 比如输入的类型(反序对的数目)
- 输入的大小, 设输入规模为
, 则算法时间一般记为
- 一般算法的分析集中于求最坏的运行时间,理由:
- 给出了对于任何输入的一个运行时间的上界,可以期望它不会变得更坏
- 对用户的时间保证
- 对于某些算法,最坏的情况经常出现
- 比如检索数据库时,要检索的数据并不存在
- “平均情况”往往和最坏情况大致一样差
- 如插入排序的平均情况和最坏情况的运行时间均为
- 如插入排序的平均情况和最坏情况的运行时间均为
- 给出了对于任何输入的一个运行时间的上界,可以期望它不会变得更坏
- 平均情况分析,需要有关输入的统计分布,一般假设为均匀分布
- 最好情况分析
- 一般无大用
# 算法性能的渐近分析
- 渐近分析分忽略依赖于机器性能的常量,其关注的是当
时, 的增长 - 低速算法在小规模输入下,可能性能更好
# 归并排序
# 归并排序的算法实现
- 分解
- 分解待排序的 n 个元素的序列形成各具有 n/2 个元素的两个子序列
- 解决
- 使用归并排序递归的排序两个字序列
- 合并
- 合并两个已排序的子序列,以产生已排序的答案
# 归并排序的伪代码实现
MERGE-SORT(A, p, r):
if p < r:
q = ⌊(p+r)/2⌋
MERGE-SORT(A, p, q)
MERGE-SORT(A, q+1, r)
MERGE(A, p, q, r)
1
2
3
4
5
6
2
3
4
5
6
- 实现过程图解
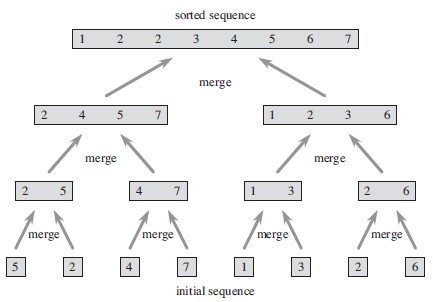
# 归并排序的时间复杂度分析
可写为递归式的形式
$$ T_{n}=\left{\begin{array}{ll} \Theta(1) & n=1 \ 2 T\left(\frac{n}{2}\right)+\Theta(n) & n>1 \end{array}\right. $$
- 其中
是由 MERGE 过程产生的
- 其中
可以通过后续章节的主定理证明
也可通过递归树法进行求解
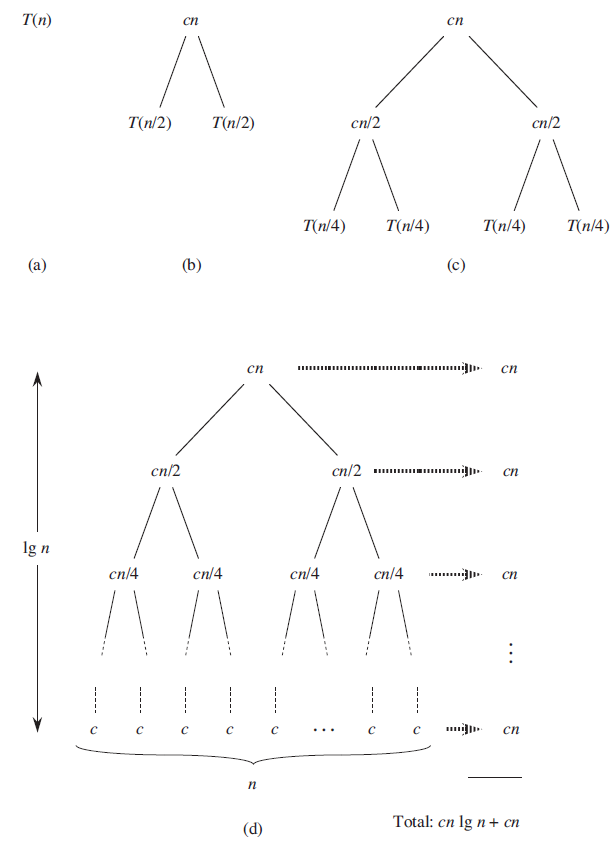
编辑 (opens new window)