
 SQL概述与数据定义
SQL概述与数据定义
# SQL 概述与数据定义
# SQL 概述
- SQL(Structured Query Language)
- 结构化查询语言,是关系数据库的标准语言
# SQL 历史
- 1970年Codd提出了关系模型之后,由于关系代数或者关系都太数学了,难以被普通用户接受,于是1973年IBM开展了System R的研制工作
- System R 以关系模型为基础,但是摈弃了数学语言,以自然语言为方向,结果诞生了结构化英语查询语言 (Structured English Query Language,SEQUEL),负责人为Don Chamberlin博士。
- 后来更名为SQL,发音不变。
- System R获得1988年度ACM“软件系统奖
| 标准 | 大致页数 | 发布日期 |
|---|---|---|
| SQL/86 | 1986.10 | |
| SQL/89(FIPS 127-1) | 120页 | 1989年 |
| SQL/92 | 622页 | 1992年 |
| SQL99(SQL 3) | 1700页 | 1999年 |
| SQL2003 | 3600页 | 2003年 |
| SQL2008 | 3777页 | 2006年 |
| SQL2011 | 2010年 |
- 目前,没有一个数据库系统能够支持SQL标准的所有概念和特性
# SQL 的特点
SELECT Sno, Grade -- 选取 学号Sno和成绩Grade
FROM SC -- 从表 SC中
WHERE Cno= ' 3 ' -- 满足条件 课程号Cno=“3”
ORDER BY Grade DESC; -- 按照 成绩Grade降序排列
1
2
3
4
2
3
4
综合统一
- 集数据定义语言(DDL),数据操纵语言(DML),数据控制语言(DCL)功能于一体。
- 可以独立完成数据库生命周期中的全部活动:
- 定义和修改、删除关系模式,定义和删除视图,插入数据,建立数据库;
- 对数据库中的数据进行查询和更新;
- 数据库重构和维护
- 数据库安全性、完整性控制,以及事务控制
- 嵌入式SQL和动态SQL定义
高度非过程化
- 非关系数据模型的数据操纵语言“面向过程”,必须指定存取路径
- SQL只要提出“做什么”,无须了解存取路径
- 存取路径的选择以及SQL的操作过程由系统自动完成
面向集合的操作方式
- 非关系数据模型采用面向记录的操作方式,操作对象是一条记录
- SQL采用集合操作方式
- 操作对象、查找结果可以是元组的集合
- 一次插入、删除、更新操作的对象可以是元组的集合
以同一种语法结构提供多种使用方式
- SQL是独立的语言
- 能够独立地用于联机交互的使用方式
- SQL又是嵌入式语言
- SQL能够嵌入到高级语言(例如C,C++,Java)程序中,供程序员设计程序时使用
- SQL是独立的语言
语言简洁,易学易用
- SQL功能极强,完成核心功能只用了9个动词
| 数据查询 | SELECT |
|---|---|
| 数据定义 | CREATE,DROP,ALTER |
| 数据操纵 | INSERT,UPDATE,DELETE |
| 数据控制 | GRANT,REVOKE |
# SQL支持关系数据库三级模式结构
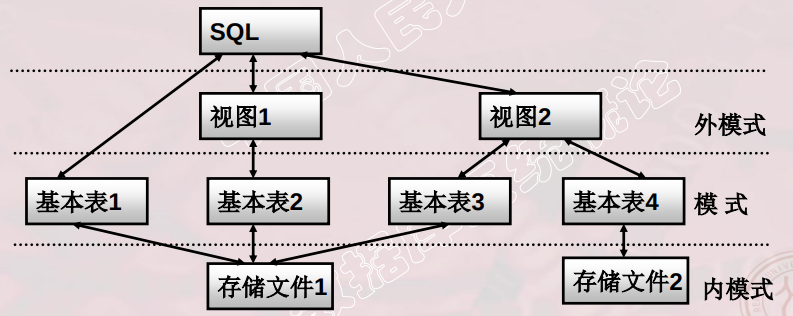
# 基本表
- 本身独立存在的表
- SQL中一个关系就对应一个基本表
- 一个(或多个)基本表对应一个存储文件
- 一个表可以带若干索引
# 存储文件
- 逻辑结构组成了关系数据库的内模式
- 物理结构对用户是隐蔽的
# 视图
- 从一个或几个基本表导出的表
- 数据库中只存放视图的定义而不存放视图对应的数据
- 视图是一个虚表
- 用户可以在视图上再定义视图
# 数据定义
[!TIP|label:本节示例中所用的数据库参照] 🔗 学生课程数据库
- SQL的数据定义功能: 定义各种数据库的“对象”
- 模式定义
- 表定义
- 视图定义
- 索引定义
!INCLUDE "./assets/tables/表3-3.html"
# 各种数据库的“对象"
现代关系数据库管理系统提供了一个层次化的数据库对象命名机制
- 一个数据库中可以建立多个模式
- 一个模式下通常包括多个表、视图和索引等数据库对象

# 数据字典
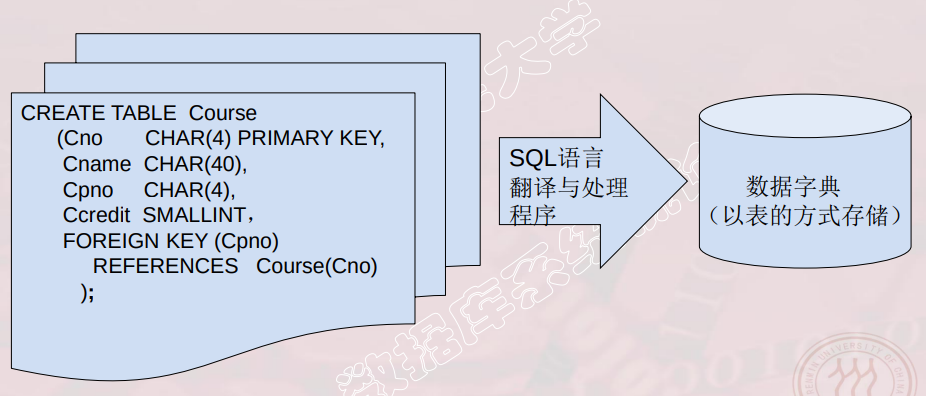
- 数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有对象的定义信息以及一些统计信息
- 关系模式、表、视图、索引的定义
- 完整性约束的定义
- 各类用户对数据库的操作权限
- 统计信息等
- 关系数据库管理系统在执行SQL的数据定义语句时,实际上就是在更新数据字典表中的相应信息
# 定义模式
# [例3.1] 为用户WANG定义一个学生-课程模式S-T
CREATE SCHEMA “S-T” AUTHORIZATION WANG
1
# [例3.2]
CREATE SCHEMA AUTHORIZATION WANG;
1
- 该语句没有指定<模式名>,<模式名>隐含为<用户名>
定义模式实际上定义了一个命名空间(或者说目录)
- 在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等
在
CREATE SCHEMA中可以接受CREATE TABLE,CREATE VIEW和GRANT子句CREATE SCHEMA <模式名> AUTHORIZATION <用户名>[<表定义子句>|<视图定义子句>|<授权定义子句>]1
# [例3.3]为用户ZHANG创建了一个模式TEST,并且在其中定义一个表 TAB1
CREATE SCHEMA TEST AUTHORIZATION ZHANG
CREATE TABLE TAB1 ( COL1 SMALLINT,
COL2 INT,
COL3 CHAR(20),
COL4 NUMERIC(10,3),
COL5 DECIMAL(5,2)
);
1
2
3
4
5
6
7
2
3
4
5
6
7
# 删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
1
CASCADE(级联)- 删除模式的同时把该模式中所有的数据库对象全部删除
RESTRICT(限制)- 如果该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行
- 仅当该模式中没有任何下属的对象时才能执行
# [例3.4]
DROP SCHEMA ZHANG CASCADE;
1
- 删除模式
ZHANG - 同时该模式中定义的表
TAB1也被删除
# 基本表的定义 ⭐
- 定义基本表
CREATE TABLE <表名> /* 基本表的名称 */
(<列名> <数据类型>[ <列级完整性约束条件> ] /*组成该表的列*/
[,<列名> <数据类型>[ <列级完整性约束条件>] ]
…
[,<表级完整性约束条件> ] );
1
2
3
4
5
2
3
4
5
- <列级完整性约束条件>:涉及相应属性列的完整性约束条件
- <表级完整性约束条件>:涉及一个或多个属性列的完整性约束条件
- 如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上
# [例3.5] 建立“学生”表Student。学号是主码,姓名取值唯一
CREATE TABLE Student
(Sno CHAR(9) PRIMARY KEY,
/* 列级完整性约束条件,Sno是主码*/
Sname CHAR(20) UNIQUE, /* Sname取唯一值*/
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
PRIMARY KEY为主码UNIQUE约束,不允许重复值
# [例3.6 ] 建立一个“课程”表Course
CREATE TABLE Course
(Cno CHAR(4) PRIMARY KEY,
Cname CHAR(40),
Cpno CHAR(4), -- 先修课
Ccredit SMALLINT,
FOREIGN KEY (Cpno) REFERENCES Course(Cno) -- cpno 为外码
-- 被参照表是 Course
-- 被参照表是 Cno
);
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
# [例3.7] 建立一个学生选课表SC
CREATE TABLE SC
(Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY (Sno,Cno), /* 主码由两个属性构成,必须作为表级完整性进行定义*/
FOREIGN KEY (Sno) REFERENCES Student(Sno), /* 表级完整性约束条件,Sno是外码,被参照表是Student */
FOREIGN KEY (Cno)REFERENCES Course(Cno) /* 表级完整性约束条件, Cno是外码,被参照表是Course*/
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 数据类型
- 关系模型中“域”的概念用数据类型来实现
- 定义表的属性时需要指明其数据类型及长度
- 选用哪种数据类型
- 取值范围
- 要做哪些运算
| 数据类型 | 含义 |
|---|---|
CHAR(n), CHARACTER(n) | 长度为n的定长字符串 |
VARCHAR(n),CHARACTERVARYING(n) | 最大长度为n的变长字符串 |
CLOB | 字符串大对象 |
BLOB | 二进制大对象 |
INT,INTEGER | 长整数(4字节) |
SMALLINT | 短整数(2字节) |
BIGINT | 大整数(8字节) |
NUMERIC(p,d) | 定点数,由p位数字(不包括符号、小数点)组成,小数后面有d位数字 |
DECIMAL(p,d), DEC(p,d) | 同NUMERIC |
REAL | 取决于机器精度的单精度浮点数 |
DOUBLE PRECISION | 取决于机器精度的双精度浮点数 |
FLOAT(n) | 可选精度的浮点数,精度至少为n位数字 |
BOOLEAN | 逻辑布尔量 |
DATE | 日期,包含年、月、日,格式为YYYY-MM-DD |
TIME | 时间,包含一日的时、分、秒,格式为HH:MM:SS |
TIMESTAMP | 时间戳类型 |
INTERVAL | 时间间隔类型 |
# 模式与表
每一个基本表需属于某个模式
定义基本表所属模式的方式:
方法一:在表名中明显地给出模式名
Create table "S-T".Student(......); /*模式名为 S-T*/ Create table "S-T".Cource(......); Create table "S-T".SC(......);1
2
3方法二:在创建模式的同时创建表
方法三:设置所属的模式
创建基本表(其他数据库对象也一样)时,若没有指定模式,系统根据搜索路径来确定该对象所属的模式
- 关系数据库管理系统会以“搜索路径”指向的模式作为数据库对象的模式名
设置搜索路径的方式
SET search_path TO "S-T",PUBLIC;1
# 修改基本表
- 基本语法
ALTER TABLE <表名>
[ADD[COLUMN] <新列名> <数据类型> [ 完整性约束 ] ]
[ADD <表级完整性约束>]
[DROP [ COLUMN ] <列名> [CASCADE| RESTRICT] ]
[DROP CONSTRAINT<完整性约束名>[ RESTRICT | CASCADE ] ]
[ALTER COLUMN <列名><数据类型> ] ;
1
2
3
4
5
6
2
3
4
5
6
- <表名>是要修改的基本表
ADD子句用于增加新列、新的列级完整性约束条件和新的表级完整性约束条件DROP COLUMN子句用于删除表中的列- 如果指定了
CASCADE短语,则自动删除引用了该列的其他对象 - 如果指定了
RESTRICT短语,则如果该列被其他对象引用,关系数据库管理系统将拒绝删除该列
- 如果指定了
DROP CONSTRAINT子句用于删除指定的完整性约束条件ALTER COLUMN子句用于修改原有的列定义,包括修改列名和数据类型
# [例3.8] 向Student表增加“入学时间”列,其数据类型为日期型
ALTER TABLE Student ADD S_entrance DATE;
1
- 不管基本表中原来是否已有数据,新增加的列一律为空值
# [例3.9] 将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数
ALTER TABLE Student ALTER COLUMN Sage INT;
1
# [例3.10] 增加课程名称必须取唯一值的约束条件
ALTER TABLE Course ADD UNIQUE(Cname);
1
# 删除基本表
DROP TABLE <表名>[RESTRICT| CASCADE];
1
RESTRICT:删除表是有限制的- 欲删除的基本表不能被其他表的约束所引用
- 如果存在依赖该表的对象,则此表不能被删除
CASCADE:删除该表没有限制- 在删除基本表的同时,相关的依赖对象一起删除
# [例3.11] 删除Student表
DROP TABLE Student CASCADE;
1
- 基本表定义被删除,数据被删除
- 表上建立的索引、视图、触发器等一般也将被删除
!INCLUDE "./assets/tables/dropTable.html"
R表示RESTRICT,C表示CASCADE- '×'表示不能删除基本表,'√'表示能删除基本表,‘保留’表示删除基本表后,还保留依赖对象
# 索引
建立索引的目的:加快查询速度
关系数据库管理系统中常见索引
- 顺序文件上的索引
- B+ 树索引
- 散列(hash)索引
- 位图索引
特点:
- B+树索引具有动态平衡的优点
- HASH索引具有查找速度快的特点
索引的创建
- 由数据库管理员或表的属主(即建立表的人)完成
索引的维护
- 由关系数据库管理系统自动完成
索引的使用
- 关系数据库管理系统自动选择合适的索引作为存取路径,用户不必也不能显式地选择索引
# 建立索引
CREATE [UNIQUE] [CLUSTER] INDEX <索引名>
ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…)
1
2
2
- <表名>:要建索引的基本表的名字
- 索引:可以建立在该表的一列或多列上,各列名之间用逗号分隔
- <次序>:指定索引值的排列次序,升序:ASC,降序:DESC。缺省值:ASC
- UNIQUE:此索引的每一个索引值只对应唯一的数据记录
- CLUSTER:表示要建立的索引是聚簇索引(一对多)
# [例3.13] 为学生-课程数据库中的Student,Course,SC三个表建立索引
Student表按学号升序建唯一索引Course表按课程号升序建唯一索引SC表按学号升序和课程号降序建唯一索引
CREATE UNIQUE INDEX Stusno ON Student(Sno);
CREATE UNIQUE INDEX Coucno ON Course(Cno);
CREATE UNIQUE INDEX SCno ON SC(Sno ASC,Cno DESC);
1
2
3
2
3
# 修改索引
ALTER INDEX <旧索引名> RENAME TO <新索引名>
1
# [例3.14] 将SC表的SCno索引名改为SCSno
ALTER INDEX SCno RENAME TO SCSno;
1
# 删除索引
DROP INDEX <索引名>;
1
- 删除索引时,系统会从数据字典中删去有关该索引的描述
# [例3.15] 删除Student表的Stusname索引
DROP INDEX Stusname;
1
编辑 (opens new window)